

IO Multiplexing
该笔记主要关注网络 I/O,关于 5 种 IO 模型的介绍,参考 IO模型
Select
select 是一种 I/O 多路复用 机制,用于同时监听多个文件描述符上的 I/O 事件就绪情况,如可读、可写或异常状态。int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
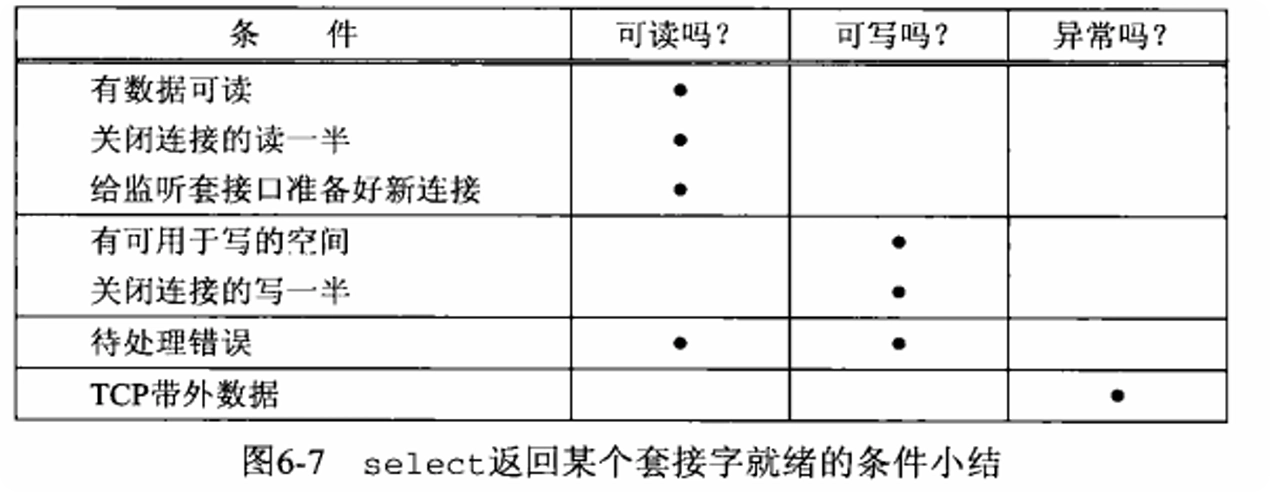
判断条件可参考 UNIX 网络编程卷一 6.3.1 章节,下图汇总了相关条件:
timeout
timeout 参数用于设置等待时间,有三种方式:
- 不等待:轮询文件描述符后立即返回,timeval 中指定时间为 0
- 等待直到有文件描述符就绪:timeval 中指定等待时间,select 会阻塞直到有文件描述符就绪或超时
- 无限等待:timeval 设置为 NULL,select 会一直阻塞直到有文件描述符就绪
struct timeval { long tv_sec; // seconds, 秒 long tv_usec; // microseconds, 微秒};
Fd Set
fd_set 通常是一个位图(bitmap),在内部实现为一个长整型数组。数组中的每一个比特位(bit)对应一个文件描述符。
这个位图的大小是固定的,由常量 FD_SETSIZE 决定(在 Linux 上通常是 1024),这个在 Linux 内核中是硬编码的,修改改 fd_set 大小需要改源码、重新编译 glibc 和内核
在编写 C 代码时,可以使用下面的宏来操作 fd_set:FD_ZERO(fd_set *fdset); // clear all bits in fdsetFD_SET(int fd, fd_set *fdset); // turn on the bit for fd in fdsetFD_CLR(int fd, fd_set *fdset); // turn off the bit for fdFD_ISSET(int fd, fd_set *fdset); // is the bit for fd on?
例如,我们希望监听文件描述符 3、5 和 8 的可读事件,可以这样设置 fd_set:fd_set read_fds;FD_ZERO(&read_fds);FD_SET(3, &read_fds); // 监听 fd 3FD_SET(5, &read_fds); // 监听 fd 5FD_SET(8, &read_fds); // 监听 fd 8select(9, &read_fds, NULL, NULL, &timeout);
当 select 执行完成后,会返回就绪文件描述符的总个数,并相应的修改 fd_set,将就绪的文件描述符的位设置为 1。为此,每次重新调用 select 前,通常需要再次设置 fd_set。
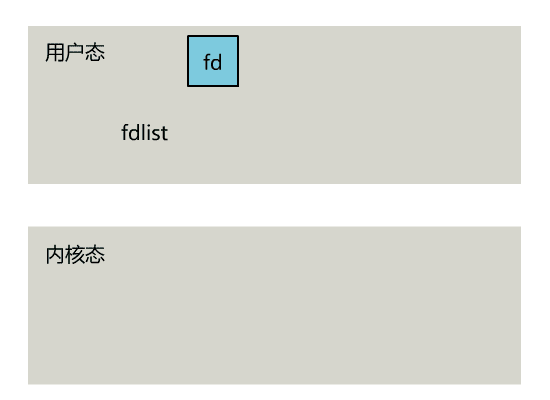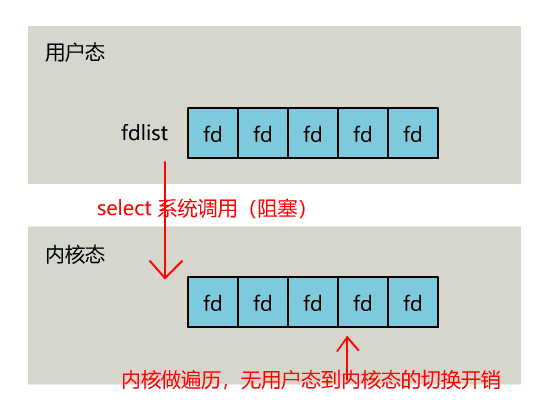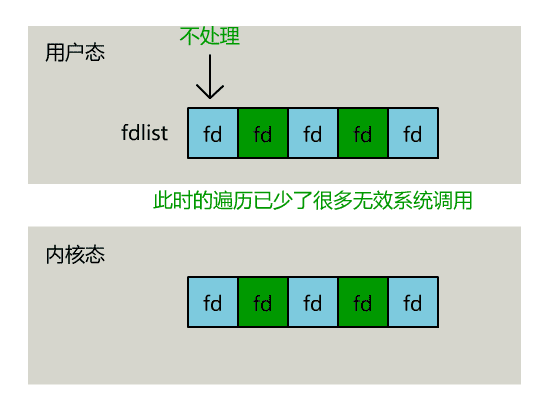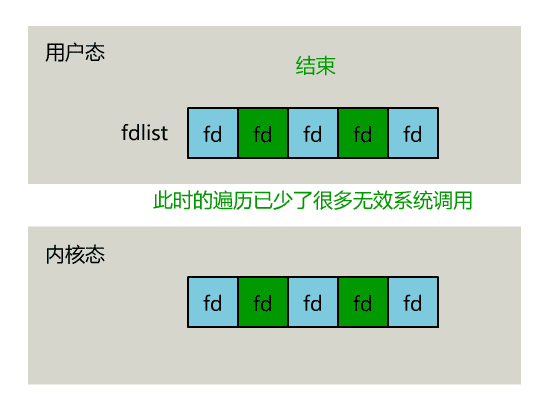
nfds
nfds(number of file descriptors)通常设置为传入的文件描述符集合中最大的文件描述符加 1,即:
Unix 网络编程卷一指出,“存在这个参数以及计算其值的额外负担纯粹是为了效率原因”。理解该参数的意义,首先假设没有 nfds 参数:
select 函数会将整个 1024-bit 位图(fd_set)复制到内核空间,在函数执行结束后再将位图复制到用户空间,这部分开销是略大的。
而一个普通进程要检查的文件描述符通常远小于 1024 个。仍以上面的代码为例,我们只关心 3, 5, 8 这三个文件描述符,后面的 1015 个 bit 并不关心,这部分数据的传输是不必要的。
通过 nfds 参数,select 可以不必拷贝完整的 1024-bit 位图,而是仅根据 nfds 决定拷贝到哪个字节为止,以节省性能和内存带宽。
Poll
poll 提供了与 select 相似的功能,内核中也是线性扫描数组,时间复杂度仍为
区别一方面是传入的 fds 大小可以自行更新(仍受系统资源限制);另外就是 API 简洁一些。
在 Linux 系统中,每个进程能打开的文件描述符数量是受限的,默认值通常为 1024,具体值可通过 ulimit 命令查看和修改。
而 select 的文件描述符上限还受限于实现层面的硬编码(通常为 FD_SETSIZE,默认 1024),即使系统允许更多 fd,select 依然无法支持。# 查看当前进程可打开的最大文件描述符数量ulimit -n# 查看系统级别允许的最大文件总数(所有进程合计)cat /proc/sys/fs/file-max
int poll(struct pollfd *fds, unsigned long nfds, int timeout);struct pollfd { int fd; // 文件描述符 short events; // events of interest on fd short revents; // events that occurred on fd};events 每个 bit 代表一种事件,和 select 类似可以划分为读、写、异常三个类别。shell 中运行 man poll 查看更具体的事件类型划分。
revents 在调用 poll 后会被内核填充,表示实际发生的事件。
Epoll
epoll 是 Linux 特有的 I/O 多路复用机制,专为处理大量文件描述符而设计。它比 select 和 poll 更高效,尤其在处理大量并发连接时。对 epoll 的详解可以参考图解 | 深入揭秘 epoll 是如何实现 IO 多路复用的!
| 特性 | select | poll | epoll |
|---|---|---|---|
| 接口标准 | POSIX | POSIX | Linux 特有 |
| fd 数量限制 | 受限(一般 1024) | 无限制 | 无限制 |
| fd 表达方式 | 位图 | 数组 | 内核结构 |
| 是否复制 fd 集合 | 每次都要 | 每次都要 | 注册一次 |
| 扫描复杂度 | O(n) | O(n) | O(1)~O(活跃 fd 数) |
Epoll LT & ET
| 维度 | 水平触发(LT) | 边缘触发(ET) |
|---|---|---|
| 触发条件 | 只要状态满足(如缓冲区非空),就持续触发 | 仅状态从 “未就绪→就绪” 时触发一次 |
| 事件通知频率 | 高(未处理完会重复通知) | 低(仅状态变化时通知) |
| 数据处理要求 | 可分多次处理,无需一次完成 | 必须一次性处理完所有当前数据 |
| 是否依赖非阻塞 I/O | 可选(阻塞 I/O 也可工作) | 必须(否则可能导致线程阻塞) |
| 编程复杂度 | 低(不易出错) | 高(需处理边缘情况,避免数据丢失) |
| 性能 | 适中 | 更高(减少通知开销) |
Ref
- 你管这破玩意叫 IO 多路复用?
- 《UNIX 网络编程》- W. Richard Stevens
IO Multiplexing