
ChⅥ 数据库应用编程
数据库连接技术
ODBC
ODBC 是由 Microsoft 在 1990 年代初开发的,用于访问各种数据库系统的标准 API。ODBC 使用 SQL 作为数据库访问语言,允许应用程序独立于任何特定 DBMS,从而使得应用程序能够与多种 DBMS 进行交互。ODBC 驱动程序是一种实现了 ODBC 接口的特定 DBMS 的库。应用程序通过 ODBC 驱动程序与 DBMS 进行通信。
- 开放式数据库互连(Open DataBase Connectivity)实现了应用程序对多种不同 DBMS 的数据库的访问,实现了数据库连接方式的变革
- 是一套基于 SQL 的,公共的,与数据库无关的 API
- 使每个应用程序利用相同的源代码就可访问不同的数据库系统
- 存取多个数据库中的数据,从而使得应用程序与数据库管理系统之间在逻辑上独立,使应用程序与数据库无关性
JDBC
JDBC 是 Java 中用于数据库连接的 API,由 Sun Microsystems(现在是 Oracle Corporation 的一部分)在 1997 年发布。JDBC 提供了一种基准,使得 Java 程序可以与多种关系数据库进行交互。JDBC 提供了一组接口和类,使得开发人员可以发送 SQL 语句并处理结果。JDBC 驱动程序是实现了 JDBC 接口的特定 DBMS 的 Java 类库。Java 程序通过 JDBC 驱动程序与 DBMS 进行通信。
JDBC 程序访问数据库的步骤
- 应用程序开始
- 导入 java.sql 包
- 加载并注册驱动程序
- 依次创建 Connection 对象、Statement 对象
- 执行 SQL 语句
- 使用 ResultSet 对象返回结果
- 依次关闭 ResultSet 对象、Statement 对象、Connection 对象
- 应用程序结束
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
// 实际开发中,密码不应该明文存储,应进行一定的数据脱敏处理。这也是为什么忘记密码时,只能重置密码,而不能查看密码的原因
public class ProcessAccountData {
ClassLoader classLoader = ProcessAccountData.class.getClassLoader();
final String sqlURL =
"jdbc:mysql://localhost:3306/free_chat?serverTimezone=GMT&useSSL=false&allowPublicKeyRetrieval=true";
final String user = "root";
final String password = "gjxMySQLPWD";
/**
* @apiNote 对数据库,进行读取,写入到validUsers
* @param validUsers 要写入账号数据的HashMap
* @throws IOException
*/
public void readAccountFile(ConcurrentHashMap<String, User> validUsers) {
try {
Class.forName("com.mysql.cj.jdbc.Driver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
return;
}
try (Connection conn = DriverManager.getConnection(sqlURL, user, password);
Statement stmt = conn.createStatement()) {
ResultSet rs = stmt.executeQuery("select * from accounts");
while (rs.next()) {
User user = new User(rs.getString("account"), rs.getString("pwd"));
validUsers.put(rs.getString("account"), user);
}
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* @apiNote 当进行注册时,将userId&pwd写入到数据库中
* @param userId 用户id
* @param pwd 用户密码
* @throws IOException
*/
public void writeAccountFile(String userId, String pwd) {
String sql = "INSERT INTO accounts (account, pwd) VALUES (?, ?)";
try (Connection conn = DriverManager.getConnection(sqlURL, user, password);) {
PreparedStatement pstmt = conn.prepareStatement(sql);
pstmt.setString(1, userId);
pstmt.setString(2, pwd);
pstmt.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
}
}
}Servlet
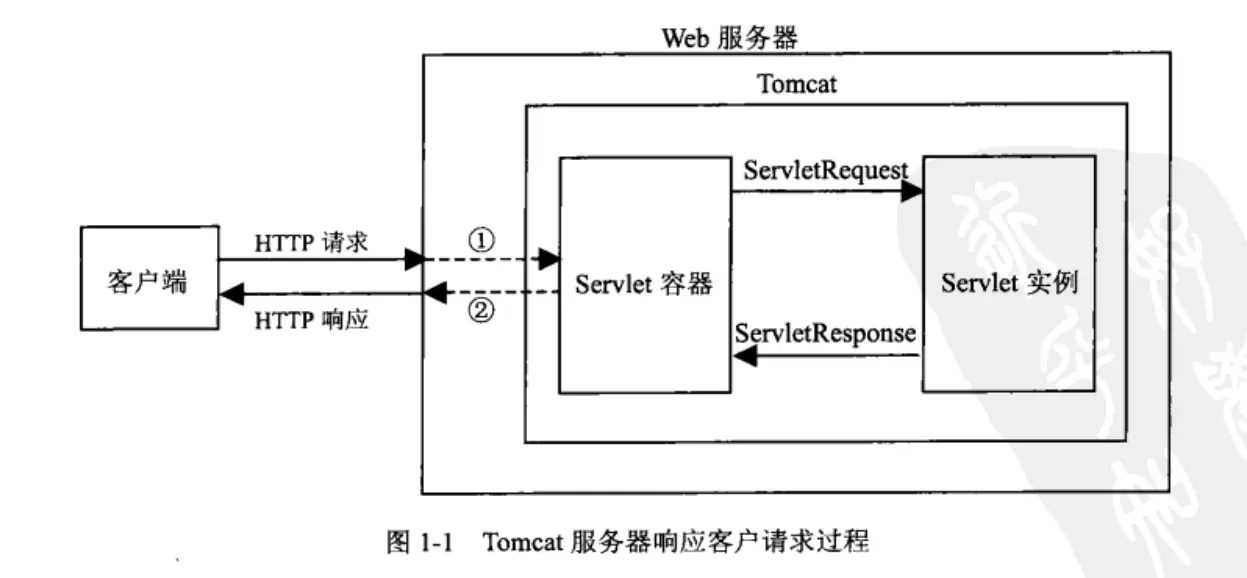
Servlet 是 Java Web 技术的核心组成部分,它是在服务器端运行的 Java 程序,用于处理来自 Web 客户端(如浏览器)的请求,并生成动态的 Web 内容。Servlet 是 Java EE 规范的一部分,但在 Java EE 8 之后,Java EE 已经转交给 Eclipse 基金会,并更名为 Jakarta EE。因此,最新的 Servlet 规范是 Jakarta Servlet。
以下是关于 Servlet 的一些关键点:
- 生命周期:Servlet 的生命周期从 Web 容器加载和实例化 Servlet 开始,经过处理一系列的请求,直到最后 Web 容器卸载 Servlet。主要的方法有 init(), service(), 和 destroy()。
- 处理请求:Servlet 可以处理来自客户端的 GET、POST 等 HTTP 请求,并根据请求生成相应的响应。请求和响应都被封装为 Java 对象,分别是 HttpServletRequest 和 HttpServletResponse。
- 线程安全:对于每个新的请求,Servlet 容器会启动一个新的线程来处理。因此,Servlet 必须被设计为线程安全的。
- 配置和上下文:Servlet 可以通过 ServletConfig 和 ServletContext 接口访问配置信息和应用程序级别的上下文。
- 会话管理:Servlet 提供了 HttpSession 接口来管理与特定用户相关的会话。
- 过滤器和监听器:Servlet API 还提供了过滤器(Filter)和监听器(Listener)等组件,可以用于拦截请求、响应,或者监听 Servlet 的生命周期事件等。
Servlet 工作流程
Mybatis
MyBatis 是一个优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 免除了几乎所有的 JDBC 代码和参数的手动设置以及结果集的检索。MyBatis 可以使用简单的 XML 或注解进行配置,并将原生信息映射至 Java 对象。MyBatis 通常被视为介于全自动 ORM 框架(如 Hibernate)和手动处理所有事情的 JDBC 之间的一种解决方案。
Mybatis 优点:
- 支持自定义 SQL、存储过程、及高级映射
- 实现自动对 SQL 的参数设置
- 实现自动对结果集进行解析和封装
- 通过 XML 或者注解进行配置和映射,大大减少代码量
- 数据源的连接信息通过配置文件进行配置
JSP
JSP 全名为 Java Server Pages,java 服务器页面。JSP 是一种基于文本的程序,其特点就是 HTML 和 Java 代码共同存在
jsp 只是 servlet 的一种特殊形式,每一个 jsp 页面就是一个 servlet 实例,通俗一点的话来说:jsp 就是 servlet,只不过 servlet 把一些业务功能剥离开来交给了或者是形成了 jsp。在我们的项目编译的时候就是把 jsp 编译成了 servlet。
JSP 比 Servlet 更方便更简单的一个重要原因就是:内置了 9 个对象!内置对象有:out、session、response、request、config、page、application、pageContext、exception
SSM 典型 Java web 开发架构
- JSP/HTML 页面发送请求
- Controller 层接收用户请求,进行响应的流程处理
- Service 层完成具体的业务逻辑
- DAO(Data Access Object)层对数据库进行操作
- 数据库
数据库存储过程
存储过程(Stored Procedure)是一种数据库的对象。由一组能完成特定功能的 SQL 语句集构成,是把经常会被重复使用的 SQL 语句逻辑块封装起来,经编译后,存储在数据库服务器端;当被再次调用时,不需要再次编译; 当客户端连接到数据库时,用户通过指定存储过程的名字并给出参数,数据库就可以找到相应的存储过程予以调用。
PostgreSQL 使用 CREATE FUNCTION 命令创建存储过程。(11 版本后可以用 CREATE PRECEDURE)
Pros
(1) 减少网络通信量
(2) 执行速度更快
(3) 更强的适应性
(4) 降低了业务实现与应用程序的耦合
(5) 降低了开发的复杂性
(6) 保护数据库元信息
(7) 增强了数据库的安全性
Cons
(1) SQL 本身是一种结构化查询语言,而存储过程本质上是过程化的程序;面对复杂的业务逻辑,过程化处理逻辑相对比较复杂;而 SQL 语言的优势是面向数据查询而非业务逻辑的处理。
(2) 如果存储过程的参数或返回数据发生变化,一般需要修改存储过程的代码,同时还需要更新主程序调用存储过程的代码。
(3) 开发调试复杂,由于缺乏支持存储过程的集成开发环境,存储过程的开发调试要比一般程序困难。
(4) 可移植性差
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
--创建存储过程
CREATE [ OR REPLACE ] FUNCTION/PROCEDURE name
([ [ argmode ] [ argname ] argtype [ { DEFAULT | = } default_expr ] [, ...] ])
[ RETURNS retype | RETURNS TABLE ( column_name column_type [, ...] ) ]
AS $$ -- $$用于声明存储过程的实际代码的开始
DECLARE
-- 声明段
BEGIN
--函数体语句
END;
$$ LANGUAGE lang_name; --$$ 表明代码的结束, LANGUAGE后面指明所用的编程语言
'''
主要参数:
(1)name:要创建的存储过程名;
(2)OR REPLACE :覆盖同名的存储过程;
(3)argmode:存储过程参数的模式可以为IN、OUT或INOUT,缺省值是IN。
(4)argname:形式参数的名字。
(5)RETURNS:返回值;RETURNS TABLE:返回二维表
'''
--删除存储过程
DROP FUNCTION [ IF EXISTS ] name ( [ [ argmode ] [ argname ] argtype [, ...] ] ) [
CASCADE | RESTRICT ]
'''
主要参数:
(1)IF EXISTS:如果指定的存储过程不存在,那么发出提示信息。
(2)name :现存的存储过程名称。
(3)argmode:参数的模式:IN(缺省), OUT, INOUT, VARIADIC。请注意,实际并不注明OUT参数,因为判断
存储过程的身份只需要输入参数。
(4)argname:参数的名字。请注意,实际上并不注明参数的名字,因为判断函数的身份只需要输入参数的数据类
型。
(5)argtype:如果有的话,是存储过程参数的类型。
(6)CASCADE:级联删除依赖于存储过程的对象(如触发器)。
(7)RESTRICT:如果有任何依赖对象存在,则拒绝删除该函数;这个是缺省值。
'''PL\pgSQL syntax
- 变量声明的语法如下:
declare
变量名 变量类型;
如果声明变量为记录类型,变量声明格式为: variable_name RECORD;
注:RECORD 不是真正的数据类型,只是一个占位符。
1
2
3
declare
count intger;
rec RECORD;- condition statement
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
'''
IF-THEN
IF-THEN-ELSE
IF-THEN-ELSEIF-ELSE
'''
IF condition THEN
statement;
END IF;
IF condition THEN
statement;
ELSE
statement;
END IF;
IF condition1 THEN
statement;
ELSEIF condition2 THEN
statement;
ELSE
statement;
END IF;- loop
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
LOOP
statement;
END LOOP [label];
LOOP
i = i + 1;
EXIT WHEN i > 10;
END LOOP;
LOOP
i = i + 1;
EXIT WHEN i > 100;
CONTINUE WHEN i < 50;
j = j + 1;
END LOOP;
WHILE condition LOOP
statement;
END LOOP
FOR i IN 1..10 LOOP
RAISE NOTICE 'i = %', i;
END LOOP;
create function Out_Record() returns RECORD as $$
declare
rec RECORD;
FOR rec IN SELECT * FROM student LOOP
raise notice '学生数据: %,%',rec.studentID,rec.studentName;
END LOOP;
return rec;
end;
$$ language plpgsql;return type
在 SQL 和 PL/pgSQL 中,函数可以返回以下几种类型的值:
标量(Scalar):这是最简单的返回类型,可以是任何基本数据类型,如 INTEGER,VARCHAR,BOOLEAN 等。
1
2
3
4
5CREATE FUNCTION add_one(INTEGER) RETURNS INTEGER AS $$ BEGIN RETURN $1 + 1; END; $$ LANGUAGE plpgsql;记录(Record):函数可以返回一个完整的记录,这个记录的结构通常与一个已存在的表相同。
1
2
3
4
5
6
7
8
9
10CREATE FUNCTION get_employee(INTEGER) RETURNS employee AS $$ BEGIN DECLARE rec employee%ROWTYPE; BEGIN SELECT * INTO rec FROM employee WHERE id = $1; RETURN rec; END; END; $$ LANGUAGE plpgsql;表(Table):函数还可以返回一个表,即多个记录。这个表可以有自定义的结构,也可以与一个已存在的表相同。
1
2
3
4
5CREATE FUNCTION get_employees() RETURNS TABLE(id INTEGER, name VARCHAR) AS $$ BEGIN RETURN QUERY SELECT id, name FROM employee; END; $$ LANGUAGE plpgsql;触发器(Trigger):在 PostgreSQL 中,触发器函数必须声明为返回 TRIGGER。
1
2
3
4
5
6
7
8CREATE FUNCTION check_update() RETURNS TRIGGER AS $$ BEGIN IF NEW.updated_at < OLD.updated_at THEN RAISE EXCEPTION 'Update timestamp must be newer'; END IF; RETURN NEW; END; $$ LANGUAGE plpgsql;复杂类型(Composite Types):函数可以返回一个自定义的复合类型。
1
2
3
4
5
6
7CREATE TYPE my_type AS (f1 integer, f2 text); CREATE FUNCTION return_compound() RETURNS my_type AS $$ BEGIN RETURN ROW(1,'test')::my_type; END; $$ LANGUAGE plpgsql;Void:如果函数不需要返回任何值,可以使用 VOID 类型。
1
2
3
4
5CREATE FUNCTION log_message(text) RETURNS VOID AS $$ BEGIN RAISE NOTICE '%', $1; END; $$ LANGUAGE plpgsql;
Examples
- 统计学生表中有多少 records
1
2
3
4
5
6
7
8
9
10
11
CREATE OR REPLACE FUNCTION countRecords ()
RETURNS integer AS $$
declare
count integer;
BEGIN
SELECT count(*) INTO count FROM STUDENT; -- INTO 用于将查询结果赋值给变量
RETURN count;
END;
$$ LANGUAGE plpgsql;
-- 执行存储过程
SELECT * FROM countRecords();- 如果 grade 大于等于 60 分视为该学生取得相应学分,编写 sql 代码统计每个 学生取得的总学分,包含学号、姓名、总学分;
Course(courseid,coursename,credit)Grade(gradeid,studentid,courseid,grade)Student(studentid,studentname,sex,age)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
CREATE OR REPLACE FUNCTION getcredit0()
RETURNS TABLE(
vsid CHAR,
vsname VARCHAR,
vscredit BIGINT
)
AS $vscredit$
BEGIN
-- 这是主查询,它将从course,grade和student表中获取信息,
-- 并计算每个学生的总学分(只包括成绩大于或等于60的课程)。
RETURN QUERY
SELECT
C.studentid AS "vsid",
C.studentname AS "vsname",
SUM(A.credit) AS "vscredit"
FROM
COURSE AS A,
GRADE AS B,
STUDENT AS C
WHERE
B.studentid = C.studentid AND
A.courseid = B.courseid AND
B.grade >= 60
GROUP BY
C.studentid;
END;
$vscredit$ LANGUAGE plpgsql;
-- 调用函数
SELECT getcredit0();- 创建一个名为 add_data(a, b,c)的存储过程实现 a+b 相加运算,并将结果放入 c
1
2
3
4
5
CREATE OR REPLACE PROCEDURE add_data(a integer,b integer,inout c integer)AS $$
Begin
c=a+b;
End;
$$LANGUAGE plpgsql;数据库触发器
触发器是一个定义在表或视图上的特殊类型的存储过程(不传递接受参数)、一个特殊的事务单位,由操作事件触发自动执行,可以实现比约束更复杂的数据完整性,用于加强数据完整性约束和业务规则
语句级触发器只执行一次(默认触发器);行级触发器每有数据变化一行就执行一次
- INSTEAD OF 触发器:事件发生时只执行触发器不执行原本的 sql 语句,一个表或视图只能有一个 INSTEAD OF 触发器
- NEW:RECORD 类型,对于行级触发器其存有 INSERT 或 UPDATE 操作产生的新数据行。对于语句级触发器其值为 NULL
- OLD:RECORD 类型,对于行级触发器其存有 DELETE 或 UPDATE 操作修改或删除的旧数据行。对于语句级触发器其值为 NULL
- TG_OP:text 类型,值为 INSERT/UPDATE/DELETE,说明引发触发器的操作
创建触发器步骤:
- 检查所依附的表或视图是否存在
- 创建触发器执行的触发器函数,返回类型为 TRIGGER
- 创建触发器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
-- 创建表
CREATE TABLE stu_score
(
sid character(10) NOT NULL,
cid character(10) NOT NULL,
score numeric(5,1),
CONSTRAINT stu_score_pkey PRIMARY KEY (sid, cid)
)
CREATE TABLE audit_score
( username character(20) , --用户名
sid character(10) ,
cid character(10) ,
updatetime text , --修改的时间
oldscore numeric(5,1), --修改前的成绩
newscore numeric(5,1) --修改后的成绩
)
-- 创建函数
CREATE OR REPLACE FUNCTION score_audit RETURNS TRIGGER
AS $score_sudits$
BEGIN
IF (TG_OP = 'DELETE') THEN
INSERT INTO audit_score SELECT user,old.sid,old.cid,OLD.score ;
RETURN OLD;
ELSIF (TG_OP = 'UPDATE') THEN
INSERT INTO audit_score
SELECT user,old.sid,old.cid,now(),OLD.score,new.score
WHERE old.sid=new.sid and old.cid=new.cid;
RETURN NEW
ELSIF (TG_OP = 'INSERT') THEN
INSERT INTO audit_score SELECT user,new.sid,new.cid,now(),null,new.score;
RETURN NEW;
END IF;
RETURN NULL;
END;
$score_audits$ LANGUAGE plpgsql;
-- 创建触发器
CREATE TRIGGER score_audit_triger
AFTER INSERT OR UPDATE OR DELETE ON stu_score
FOR EACH ROW EXECUTE PROCEDURE score_audit();
-- 修改触发器
ALTER TRIGGER score_audit_trigger ON stu_score RENAME TO score_audit_trig;
-- 删除触发器
DROP TRIGGER [ IF EXISTS ] name ON table_name [ CASCADE | RESTRICT ]
DROP TRIGGER IF EXISTS score_audit_trig ON stu_score CASCADE;数据库游标
游标是一种存放了查询数据库表返回的数据记录的临时的数据库对象,包含查询结果和指针,提供了处理结果集中每一条记录的机制,它总是与一条查询 SQL 语句相关联
1
2
3
4
5
6
7
8
9
10
11
12
13
-- 声明游标
curStudent CURSOR FOR SELECT * FROM student;
curStudentOne CURSOR (key integer)7y IS SELECT * FROM student WHERE SID = key;
-- 打开游标
OPEN curVars1 FOR SELECT * FROM student WHERE SID = mykey;
OPEN curVars1 FOR EXECUTE 'SELECT * FROM ' || quote_ident($1);
OPEN curStudent;
OPEN curStudentOne ('20160230302001');
-- 使用游标提取值
FETCH curVars1 INTO rowvar; --rowvar为行变量
FETCH curStudent INTO SID, Sname, sex;
-- 关闭游标
CLOSE cursorName;