

Network IO Models
I/O Overview
I/O 即输入输出(Input/Output),核心目标是实现数据的交换与控制。从本质上来说,IO 操作主要涉及两个阶段:
I/O Stages
Kernel Space(内核空间)和 User Space(用户空间)是操作系统中两个重要的内存区域。
- 内核空间是操作系统核心代码运行的区域,具有更高的权限,可以直接访问硬件资源
- 用户空间则是应用程序运行的区域,权限较低,不能直接访问硬件资源。通常需要通过系统调用执行特权操作
┌─────────────────────────────────────────────────────────┐│ User Space 0x0000000000000000 - 0x00007FFFFFFFFFFF ││ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ││ │ Stack Buffer│ │ Heap Buffer │ │ mmap Buffer │ ││ └─────────────┘ └─────────────┘ └─────────────┘ │└─────────────────────────────────────────────────────────┘┌─────────────────────────────────────────────────────────┐│ Kernel Space 0xFFFF800000000000 - 0xFFFFFFFFFFFFFFFF ││ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ││ │Socket Buffer│ │ Page Cache │ │ DMA Buffer │ ││ └─────────────┘ └─────────────┘ └─────────────┘ │└─────────────────────────────────────────────────────────┘- 数据准备阶段:等待数据到达并存入 kernel buffer
- 对于网络 I/O,通常是等待网络数据包到达网卡,经过内核协议栈处理并放入 socket 接收缓冲区时,这一阶段才算完成
- 数据复制阶段:将数据从 kernel buffer 复制到 user buffer,在这一阶段,数据从内核态进入用户态,供应用程序进一步处理
一次 I/O 操作各阶段的流程可以参考下图:
I/O Models
基于两个阶段的处理方式差异,可以将 I/O 操作分为以下几种模型,前 4 种模型都属于同步 I/O 模型,最后一种是异步 I/O 模型。
| IO 模型 | 数据准备阶段 | 数据复制阶段 |
|---|---|---|
| 阻塞 IO | 阻塞等待 | 同步复制 |
| 非阻塞 IO | 非阻塞轮询 | 同步复制 |
| IO 多路复用 | 阻塞等待多个源 | 同步复制 |
| 信号驱动 IO | 异步通知 | 同步复制 |
| 异步 IO | 异步等待 | 异步复制 |
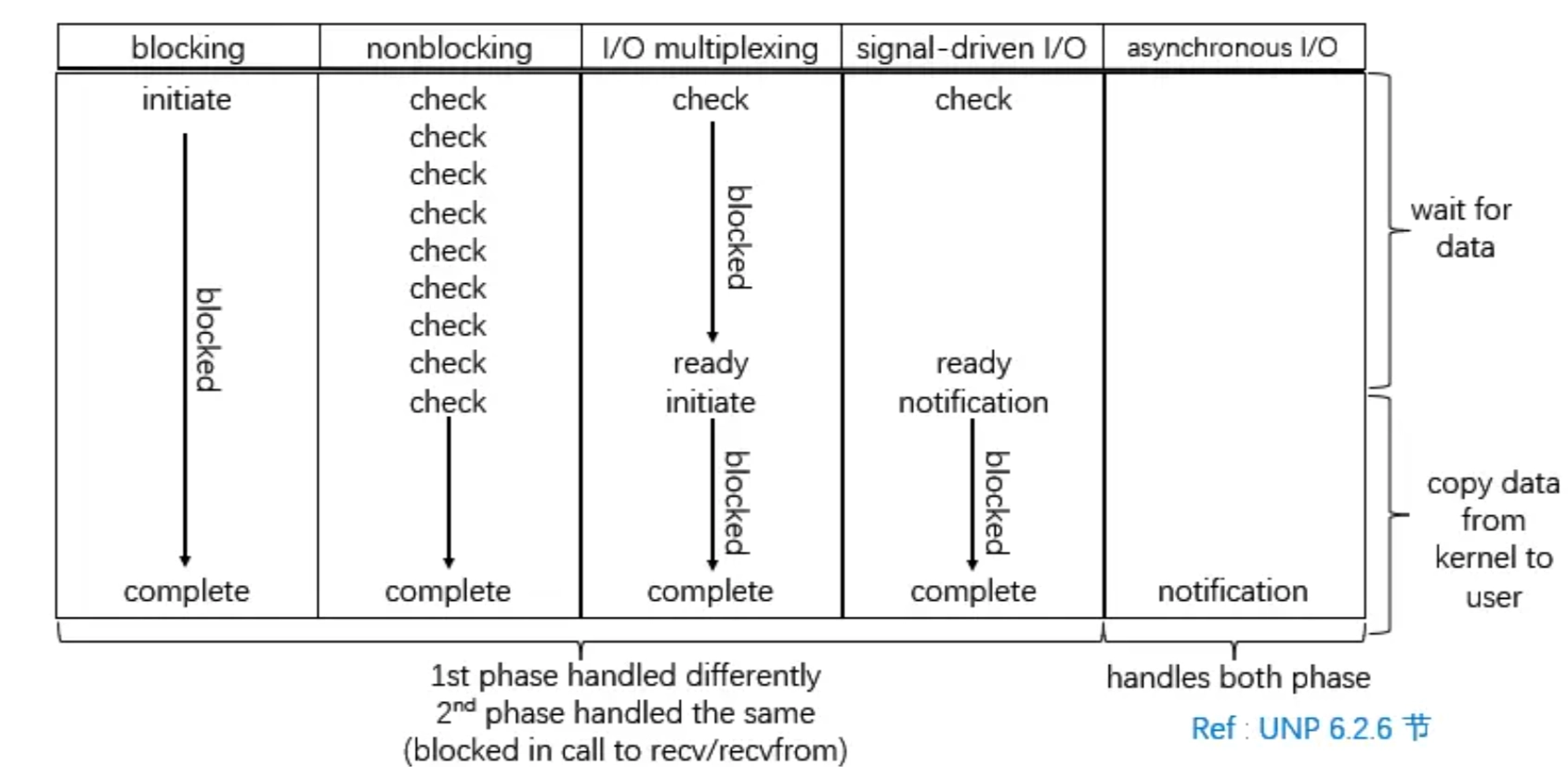
Blocking I/O
阻塞 IO 是最基本的 IO 类型。使用这种模型进行数据接收的时候,在数据没有到之前程序会一直等待。从 OS 角度来看,如果数据未准备好,调用线程/进程会进入阻塞状态(blocked)。

States Of Process & Thread: ProcessvsThread & ProcessvsThread
单线程阻塞
对于阻塞 I/O 模型来说,下面是最简单的一个网络服务器实现:单线程处理所有连接。#include <sys/socket.h>#include <netinet/in.h>#include <stdio.h>#include <unistd.h>void single_thread_server() { int server_fd = socket(AF_INET, SOCK_STREAM, 0); struct sockaddr_in address; address.sin_family = AF_INET; address.sin_addr.s_addr = INADDR_ANY; address.sin_port = htons(8080); bind(server_fd, (struct sockaddr*)&address, sizeof(address)); listen(server_fd, 3); while (1) { int client_fd = accept(server_fd, NULL, NULL); // 阻塞等待连接 char buffer[1024]; while (1) { int bytes = recv(client_fd, buffer, 1024, 0); // 阻塞读取 if (bytes <= 0) break; send(client_fd, buffer, bytes, 0); // 回显数据 close(client_fd); // 只有当前客户端断开连接后,才能处理下一个客户端 } }}
多线程阻塞模型
对此,可以使用多线程提高并发情况下的处理能力。每当有新的客户端连接时,创建一个新线程来处理该连接。
这里提供一个 Java 例程演示该模型的实现。在代码中,主函数创建了一个固定大小的线程池后等待客户端连接。每当有新的客户端连接时,主线程会将该连接交给线程池中的一个线程处理。每个线程会阻塞等待客户端发送数据,并将接收到的数据回显给客户端。import java.io.*;import java.net.*;import java.util.concurrent.*;public class BioServer { public static void main(String[] args) throws IOException { ExecutorService executor = Executors.newFixedThreadPool(100); // 固定线程池 ServerSocket serverSocket = new ServerSocket(8088); // 监听 8088 端口 while (!Thread.currentThread().isInterrupted()) { Socket clientSocket = serverSocket.accept(); // 阻塞等待客户端连接 executor.submit(new ConnectionHandler(clientSocket)); // 将连接交给线程池处理 } executor.shutdown(); serverSocket.close(); }}class ConnectionHandler implements Runnable { private final Socket socket; public ConnectionHandler(Socket socket) { this.socket = socket; } public void run() { try ( BufferedReader in = new BufferedReader( new InputStreamReader(socket.getInputStream())); BufferedWriter out = new BufferedWriter( new OutputStreamWriter(socket.getOutputStream())); ) { String line; while ((line = in.readLine()) != null) { // 阻塞读取 System.out.println("Received: " + line); out.write("Echo: " + line); out.newLine(); out.flush(); } } catch (IOException e) { System.err.println("Connection error: " + e.getMessage()); } finally { try { socket.close(); // 关闭连接 } catch (IOException ignore) {} } }}
这种模型的优点是编程模型简单,易于理解与调试,面对少量连接时使用该模型是比较合适的选择。
其限制也比较明显,即线程是比较昂贵的资源,当面对较多的连接时,可能导致系统资源耗尽。C10K问题就是在这种模型下出现的。
美团技术团队也在Java NIO 浅析中分析了该模型的限制
现在的多线程一般都使用线程池,可以让线程的创建和回收成本相对较低。在活动连接数不是特别高(小于单机 1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。
不过,这个模型(BIO 模型)最本质的问题在于,严重依赖于线程。但线程是很"贵"的资源,主要表现在:
- 线程的创建和销毁成本很高,在 Linux 这样的操作系统中,线程本质上就是一个进程。创建和销毁都是重量级的系统函数。
- 线程本身占用较大内存,像 Java 的线程栈,一般至少分配 512K ~ 1M 的空间,如果系统中的线程数过千,恐怕整个 JVM 的内存都会被吃掉一半。
- 线程的切换成本是很高的。操作系统发生线程切换的时候,需要保留线程的上下文,然后执行系统调用。如果线程数过高,可能执行线程切换的时间甚至会大于线程执行的时间,这时候带来的表现往往是系统 load 偏高、CPU sy 使用率特别高(超过 20%以上),导致系统几乎陷入不可用的状态。
- 容易造成锯齿状的系统负载。因为系统负载是用活动线程数或 CPU 核心数,一旦线程数量高但外部网络环境不是很稳定,就很容易造成大量请求的结果同时返回,激活大量阻塞线程从而使系统负载压力过大。
所以,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。随着移动端应用的兴起和各种网络游戏的盛行,百万级长连接日趋普遍,此时,必然需要一种更高效的 I/O 处理模型。
Non-Blocking I/O
非阻塞 I/O 允许应用程序在发起 I/O 操作后立即返回,而不会因数据尚未准备好而阻塞,这就允许用户进程自由去做别的事,最简单的例子就是轮询(polling),应用程序可以定期检查数据是否准备好。
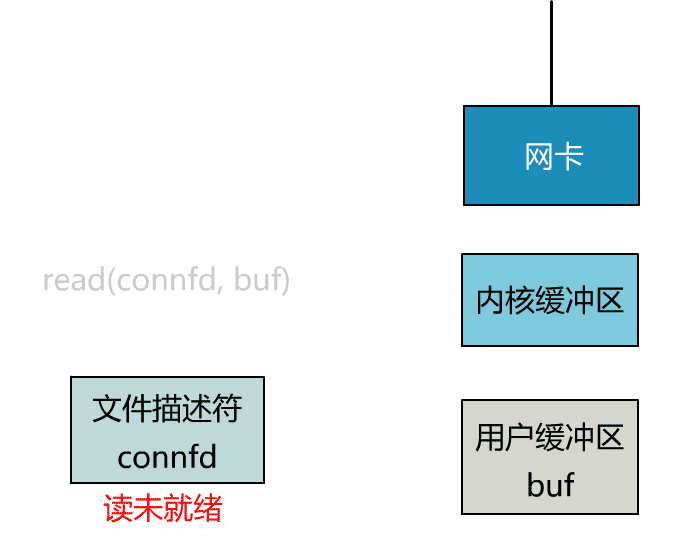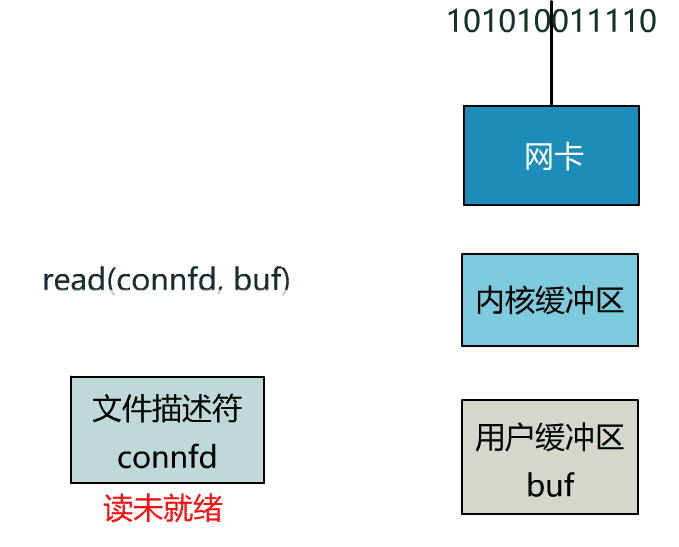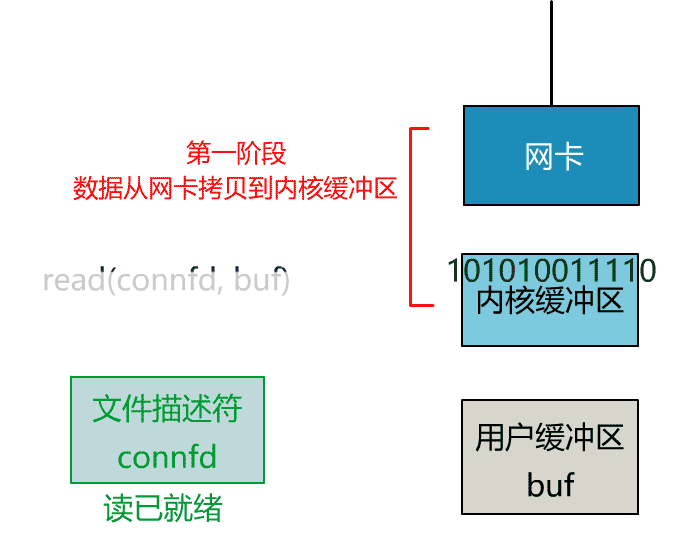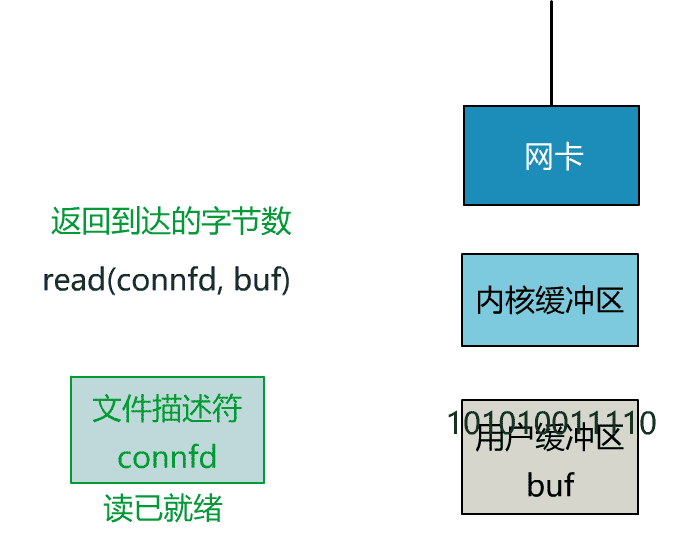
仍以网络 I/O 为例,Windows/Linux 下的套接字默认是阻塞的,应用程序可以通过fcntl/ioctl函数将套接字设置为非阻塞。// 如果 fd 已设置了其他标志位,可以先使用 fcntl 获取当前标志位,然后用位或操作添加 O_NONBLOCK 标志位int safe_set_nonblocking(int fd) { int flags = fcntl(fd, F_GETFL, 0); return fcntl(fd, F_SETFL, flags | O_NONBLOCK);}
当调用 Socket 操作函数时,如果操作不能立即完成,系统调用会立即返回一个错误,并将错误码(errno)设置为EWOULDBLOCK,含义为 would block,可以对应下面表格的阻塞触发条件。
| 类别 | 操作函数 | 阻塞触发条件(TCP/UDP) |
|---|---|---|
| 读操作 | read readv recv recvfrom recvmsg | TCP:接收缓冲区无足够数据 UDP:接收缓冲区为空(UDP 需整报读取) |
| 写操作 | write writev send sendto sendmsg | TCP:发送缓冲区无足够空间 UDP:可能直接丢弃报文,视实现而定 |
| 接受连接 | accept | 无新连接到来(监听套接字阻塞) |
| 发起连接 | connect | TCP:三次握手未完成 |
部分实现中将错误码定义为 EAGAIN,顾及历史原因,POSIX 标准允许这两种错误码的使用,在大多数系统中,这两个错误代码是等价的,具体可以<sys/errno.h>头文件中查看
connect函数稍特别一点,每次调用函数发起 TCP 连时,[[Ch5-2TransportLayer#three-way handshake|TCP 三次握手]]会阻塞调用进程至少一个 RTT 的时间,如果连接无法立刻完成(大多数情况下不会),errno 被设置为 EINPROGRESS,表示“连接还在进行中”
如下代码是最简单的轮询模型。,这种简单的实现从整体上来看,用户进程还是阻塞在while循环上,发现不能读/写就立刻继续下一轮检查while (1) { ssize_t n = recv(fd, buf, sizeof(buf), MSG_DONTWAIT); if (n > 0) { // 处理接收到的数据 } else if (n == -1 && errno == EWOULDBLOCK) { // 可以在这里做其他事情, 例如: // 1. 心跳检查:如果没有数据可读,可以发送心跳包,根据业务逻辑触发重连/资源清理 check_heartbeat(); // 2. 更新Log update_log(); sleep(1); // 等待一段时间后重试 }}
在 Blocking IO 中为了提高并发能力,使用多线程为每一个建立的 socket 分配一个线程去阻塞 read/write,其缺点前文也已解释,当面对百万的连接数时,大量线程会耗尽系统资源。引入 Non Blocking IO 后,我们可以在一个线程,同时处理多个客户端连接:#define MAX_CLIENTS 100 // 设置最多复用100个客户端连接int server_fd;// 存放客户端连接的文件描述符,初始化为-1,表示该位置没有客户端连接;int client_fd_set[MAX_CLIENTS];void multiplexing_server() { while (1) { for (int i = 0; i < MAX_CLIENTS; i++) { if (client_fd_set[i] == -1) continue; // 如果该位置没有客户端连接,跳过 ssize_t bytes_read = recv(client_fd_set[i], buf, sizeof(buf), MSG_DONTWAIT); if (bytes_read > 0) { // 处理接收到的数据 process_data(buf, bytes_read); } else if (bytes_read == -1 && errno == EWOULDBLOCK) { // 没有数据可读,可以在这里做其他事情,例如心跳检查、更新日志等 } else if (bytes_read == 0) { // 客户端断开连接,清理资源 close(client_fd_set[i]); } } }}
现在服务器一般为多核处理器,上述代码中的process_data内为 CPU 密集型操作,可以提交到线程池中处理,以充分利用多核 CPU 的并行处理能力。
I/O Multiplexing
I/O 多路复用(I/O Multiplexing)允许单个线程/进程同时监控多个文件描述符的状态变化。通过这种方式,应用程序可以在一个线程中处理多个连接,而不需要为每个连接创建独立的线程。
上面代码中的 while 循环也实现了类似多路复用的功能,但它在循环内每次调用 recv 都是一次从用户态到内核态的上下文切换,而更合理的方式是将轮询的操作从用户空间移动到内核空间,通过一次系统调用就能监控多个文件描述符的状态变化,从根本上减少了用户态和内核态之间的切换开销。
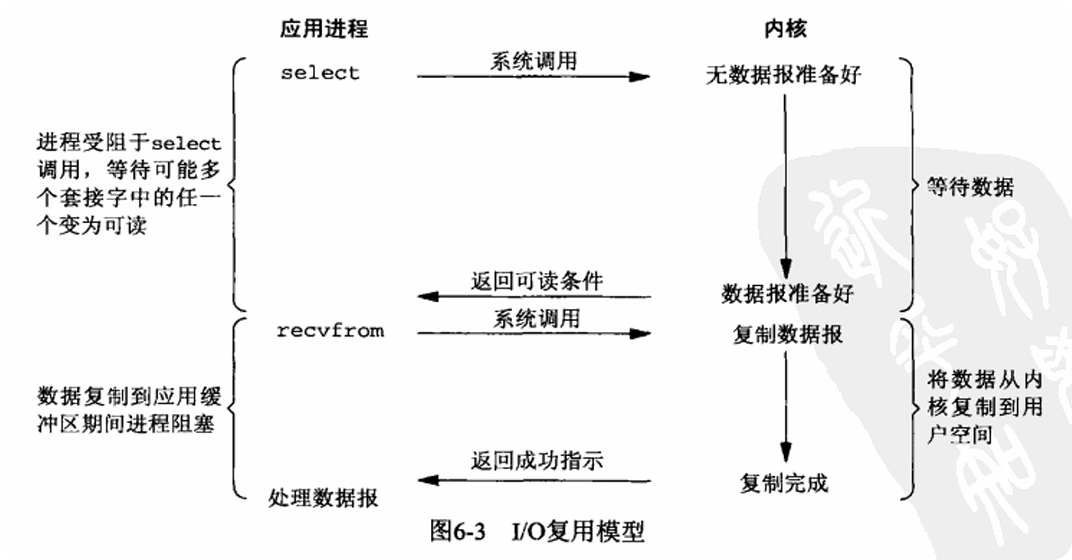
以 Linux 为例,内核提供了 select、poll 和 epoll 三个函数(其中 epoll 为 Linux 特有)。首先将一组文件描述符注册到内核中,内核负责监控这些文件描述符的状态变化。当其中某个文件描述符变为可读或可写时,内核会通知应用程序,应用程序可以通过一次系统调用获取所有就绪的文件描述符,从而避免了频繁的上下文切换。详细介绍参考[[IO 多路复用]]。
Signal-Driven I/O
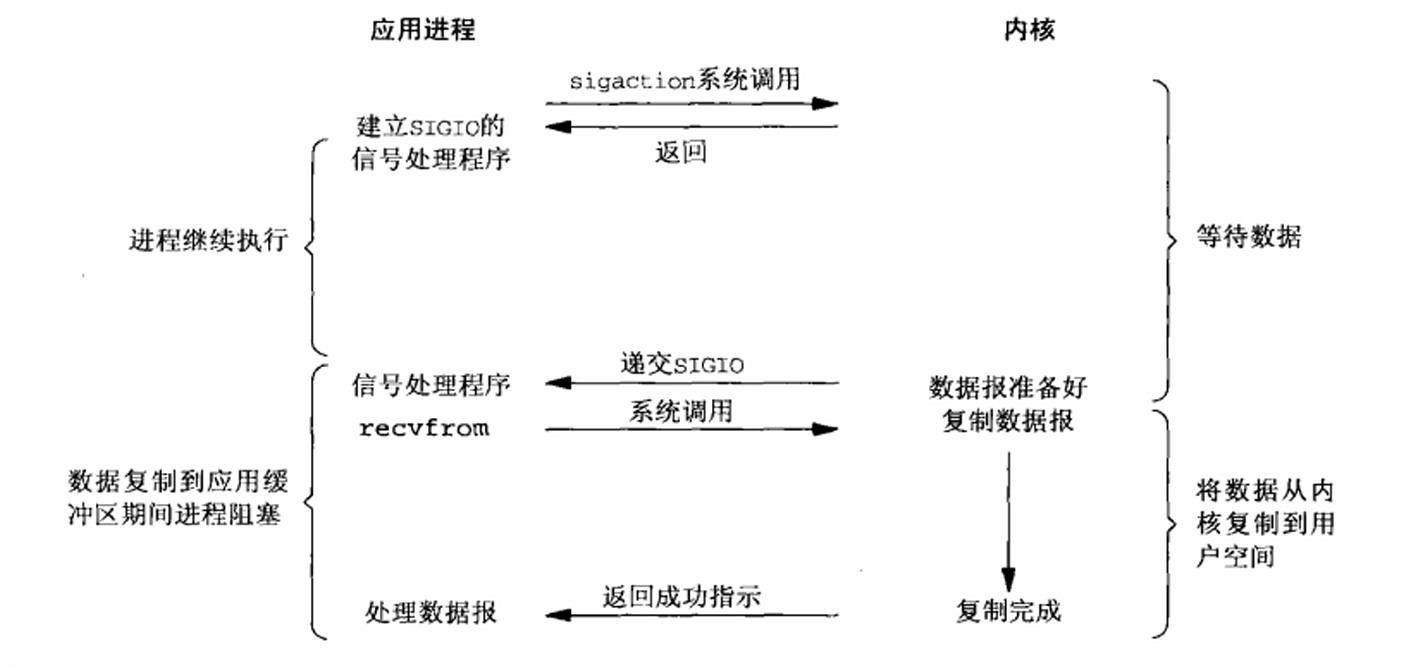
信号驱动的 IO 在进程开始的时候注册一个信号处理的回调函数,进程继续执行。当数据到来时,通知目标进程进行 IO 操作(signal handler)。
Asynchronous I/O
“异步”这个词在技术讨论中常被用于描述两个不同层面的概念,这容易引起混淆:
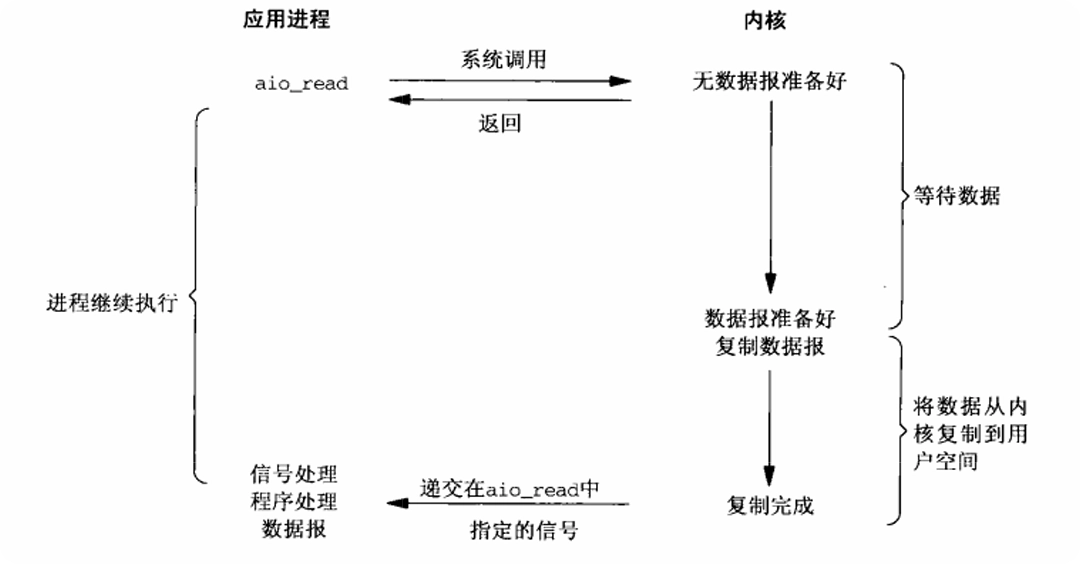
- 操作系统层面的 I/O 模型:例如本文介绍的 AIO。在此模型中,从数据准备到数据复制的整个过程都由内核完成,应用只需发起请求,然后等待内核的完成信号即可。
- 应用程序层面的编程模型:框架提供的 API 是异步的,但框架所调用的操作系统接口是同步非阻塞。
异步 IO 与前面的信号驱动 IO 相似,其区别在于信号驱动 IO 当数据到来的时候,使用信号通知注册的信号处理函数,而异步 IO 则在数据复制完成的时候才发送信号通知注册的信号处理函数。
References
- 你管这破玩意叫 IO 多路复用?
- 怎样理解阻塞非阻塞与同步异步的区别? - 学刑法的程序员的回答 - 知乎
- Java NIO 浅析 - 美团技术团队
- 《UNIX 网络编程》- W. Richard Stevens
Network IO Models