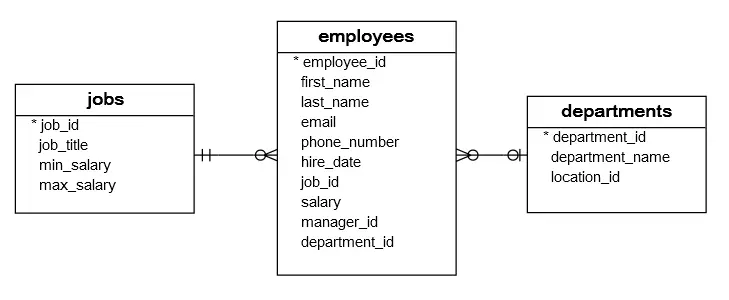
项目开发中,在进行数据库表结构设计时,会根据业务需求及业务模块之间的关系,分析并设计表结构,由于业务之间相互关联所以各个表结构之间也存在着各种联系,基本上分为三种: 一对一 one to one 如用户与用户详情的关系 多用于单表拆分,将一张表的基础字段和扩展字段分开存储,减少数据冗余,提高数据库性能.可在任意一方添加外键关联另一方的主键,并且外键字段设置 UNIQUE 约束. 一对多(多对一) one to many 如一个部门对应多个员工,一个员工只能对应一个部门. 这种关系一般是通过在多的一方添加外键来实现的.(员工表中设置部门 id 作为外键,指向部门表中的主键) 多对多 many to many 如一个学生可以选择多个课程,一个课程也可以被多个学生选择. 这种关系一般是通过添加第三张表来实现的.(学生表,课程表,学生课程表),中间表中设置学生 id 和课程 id 作为外键,指向学生表和课程表的主键.
为方便理解,以下以员工表和部门表为例进行说明.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
SELECT * FROM employees; +----+-------+--------------+ | ID | Name | DepartmentID | +----+-------+--------------+ | 1 | John | 100 | | 2 | Alice | 200 | | 3 | Bob | 100 | | 4 | David | 300 | +----+-------+--------------+ SELECT * FROM departments; +-----+-----------+ | ID | Name | +-----+-----------+ | 100 | Sales | | 200 | Marketing | | 300 | HR | +-----+-----------+
多表查询概述
合并查询(笛卡尔积,显示所有组合结果,不常用) SELECT * FROM table1,table2; 消除无效组合(内连接) SELECT * FROM employee, department WHERE employee.dept_id = department.id;
-- 查询员工姓名,以及对应的部门名称-- 隐式SELECT e.Name,d.Name FROM employees AS e, departments AS d WHERE e.DepartmentID = d.ID;+-------+-----------+| Name | Name |+-------+-----------+| John | Sales || Alice | Marketing || Bob | Sales || David | HR |+-------+-----------+-- 显式SELECT e.Name,d.Name FROM employees AS e INNER JOIN departments AS d ON e.DepartmentID = d.ID;+-------+-----------+| Name | Name |+-------+-----------+| John | Sales || Alice | Marketing || Bob | Sales || David | HR |+-------+-----------+
sql inner join 3 tables example
1 2 3 4 5 6 7 8 9 10 11 12
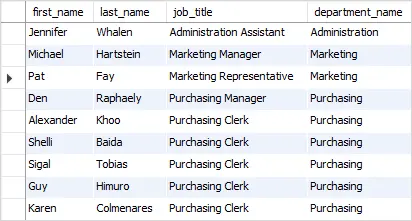
SELECT first_name, last_name, job_title, department_name FROM employees e INNER JOIN departments d ON d.department_id = e.department_id INNER JOIN jobs j ON j.job_id = e.job_id WHERE e.department_id IN (1, 2, 3);
外连接查询 Outer Join
分为左外连接、右外连接、全外连接(Left Join, Right Join, Full Join)
-- left joinSELECT e.Name,d.Name FROM employees AS e LEFT JOIN departments AS d ON e.DepartmentID = d.ID;-- right joinSELECT e.Name,d.Name FROM departments AS d RIGHT JOIN employees AS e ON e.DepartmentID = d.ID;-- 以上两句等价+-------+-----------+| Name | Name |+-------+-----------+| John | Sales || Alice | Marketing || Bob | Sales || David | HR |+-------+-----------+
自连接查询 Self Join
当前表与自身的连接查询,自连接必须使用表别名;自连接查询,可以是内连接查询,也可以是外连接查询
1 2 3 4 5 6 7 8 9
SELECT A.Name,B.NameFROM employees AJOIN employees BON A.DepartmentID = B.DepartmentID && A.Name < B.Name;+------+------+| Name | Name |+------+------+| Bob | John |+------+------+
SELECT 字段列表 FROM 表A ...UNION [ALL]SELECT 字段列表 FROM 表B ...
Note: UNION 会自动去重, UNION ALL 不会去重;联合查询比使用 or 效率高,不会使索引失效
1 2 3 4 5 6 7 8 9 10 11 12
SELECT Name FROM employees UNION SELECT Name FROM departments;+-----------+| Name |+-----------+| John || Alice || Bob || David || Sales || Marketing || HR |+-----------+
子查询 Subquery
SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2); 在 SQL 中,子查询(Subquery)是嵌入在其他 SQL 查询中的查询,又称嵌套查询。 子查询可以用在各种 SQL 语句中,如 SELECT、INSERT、UPDATE、DELETE,以及在 WHERE 或 HAVING 子句中。
1 2 3
SELECT EmployeeName, SalaryFROM EmployeesWHERE Salary > (SELECT AVG(Salary) FROM Employees);
-- 标量子查询SELECT * FROM employees WHERE Salary > (SELECT AVG(Salary) FROM employees);-- 列子查询SELECT *FROM employeesWHERE Salary IN (SELECT Salary FROM employees WHERE DepartmentID = 100);SELECT *FROM employeesWHERE Salary > ALL (SELECT Salary FROM employees WHERE DepartmentID = 100);SELECT *FROM employeesWHERE Salary > ANY (SELECT Salary FROM employees WHERE DepartmentID = 100);-- 行子查询SELECT *FROM employeesWHERE (salary, manager) = (SELECT salary,manager FROM employee WHERE name = 'xxx');-- 表子查询SELECT e.*, d.*FROM (SELECT * FROM employees WHERE entrydate > '2006-01-01') AS eLEFT JOIN dept AS dON e.dept = d.id;
-- Manual transactionSET @@autocommit = 0;SELECT * FROM employees WHERE ID = 1;UPDATE employees SET Salary = 1000 WHERE ID = 1;UPDATE employees SET Salary = 2000 WHERE ID = 2;COMMIT;-- 如果出现错误,可以使用 ROLLBACK 回滚事务ROLLBACK;-- 使用START/BEGIN TRANSACTIONSTART TRANSACTION; -- 或者 BEGIN;statement1;statement2;COMMIT;
lost update Transaction A and Transaction B read and updates the same data, The update of Transaction A is lost because Transaction B overwrites it.
dirty read A transaction reads data written by a concurrent uncommitted transaction.
nonrepeatable read A transaction re-reads data it has previously read and finds that data has been modified by another transaction (that committed since the initial read).
phantom read A transaction re-executes a query returning a set of rows that satisfy a search condition and finds that the set of rows satisfying the condition has changed due to another recently-committed transaction.
serialization anomaly The result of successfully committing a group of transactions is inconsistent with all possible orderings of running those transactions one at a time.