
DataBase Base_基础概念&SQL语法
MySQL Overview
数据库相关概念
数据库 : 数据库(DataBase,Scheme)就是信息的集合或者说数据库是由数据库管理系统管理的数据的集合。
数据库管理系统 : 数据库管理系统(Database Management System)是一种操纵和管理数据库的大型软件,通常用于建立、使用和维护数据库。
数据库系统 : 数据库系统(Database System)通常由软件、数据库和数据管理员(DBA)组成。
数据库管理员 : 数据库管理员(Database Administrator)负责全面管理和控制数据库系统。
启动 & 客户端连接
MySQL80 服务将开始监听特定的端口(默认是 3306),等待客户端的连接请求。一旦接收到请求,它就会处理这些请求,执行 SQL 查询,返回查询结果
1
2
3
## 启动&停止 Service
net start mysql80
net stop mysql80客户端连接数据库的方式:
- 命令行:
mysql -h 主机名 -P 端口号 -u 用户名 -p 密码 - 图形化工具:Navicat、SQLyog、SQL Server Management Studio
数据模型
数据模型可以分为两种.关系型数据模型和非关系型数据模型
关系型数据模型
关系型数据模型(RDBMS,Relational Database Management System):关系型数据库模型是基于关系(表)的数据模型,使用表格来组织和存储数据。最常见的关系型数据库是 MySQL、Oracle、SQL Server 等。
ps:table 是关系型数据库的术语,对应的中文是表,也可以称为关系,由行和列组成。
在 SQL 中,"record"和"field"是两个基本的概念,它们分别对应于数据库表中的行和列。
Record:在数据库中,一个 record(也被称为 row 或 tuple)代表一组相关的数据,例如一个用户的信息或一个订单的详情。一个 record 包含了一组 field,每个 field 存储了一项特定的信息,例如用户的名字或订单的价格。
Field:在数据库中,一个 field(也被称为 field 或 attribute)代表一种类型的数据,例如所有用户的名字或所有订单的价格。一个 field 在一个表中是垂直的,它包含了一个特定类型的所有值。
例如,考虑一个简单的 table,它有两个 field(“User ID"和"User Name”)和两个 record:
| User ID | User Name |
|---|---|
| 1 | Alice |
| 2 | Bob |
在这个例子中,"1"和"Alice"是第一个 record,"2"和"Bob"是第二个 record。"User ID"和"User Name"是两个 field。
非关系型数据模型
非关系型数据模型(NoSQL):非关系型数据库模型是一种非结构化的数据模型,不使用表格来组织和存储数据。它们可以是键值对存储、文档存储、列存储、图形数据库等。常见的非关系型数据库有 MongoDB、Redis、Cassandra 等。

SQL Grammer
Overview
单行或多行书写,以分号结尾
SQL 语句可以用空格和缩进来增强可读性
SQL 语句不区分大小写,关键字建议使用大写
Comment:单行注释(-- comment);多行注释(/_ comment _/)
Category:DDL,DML,DQL,DCL
Data type
数值类型
| 数据类型 | 内存大小(Byte) |
|---|---|
TINYINT | 1 |
SMALLINT | 2 |
MEDIUMINT | 3 |
INT | 4 |
BIGINT | 8 |
FLOAT | 4 |
DOUBLE | 8 |
DECIMAL(M, N) | 取决于 M和 N |
数据类型后面可加 UNSIGNED修饰,例如 age TINYINT UNSIGNED
对于 DECIMAL(M, N)类型,M是数字的最大总位数,N是小数点后的位数。数值范围取决于 M和 N的值。如 123.45,M=5,N=2
字符串类型
| 数据类型 | 大小 | 描述 |
|---|---|---|
| CHAR | 0-255Bytes | 定长字符串 |
| VARCHAR | 0-65535Bytes | 变长字符串 |
| BLOB | 0-65535Bytes | 二进制形式的长文本数据 |
| TEXT | 0-65535Bytes | 长文本数据 |
char(10) 会占用 10 个字符的存储空间,不足 10 个字符会使用空格补齐;性能高于 varchar
varchar(10) 会根据实际存储的字符数来占用存储空间,不会浪费空间
Date & Time
| 类型 | 格式 | 范围 |
|---|---|---|
| DATE | YYYY-MM-DD | 1000-01-01 到 9999-12-31 |
| TIME | HH:MM:SS | -838:59:59 到 838:59:59 |
| YEAR | YYYY | 1901 到 2155, 以及 0000 |
| DATETIME | YYYY-MM-DD HH:MM:SS | 1000-01-01 00:00:00 到 9999-12-31 23:59:59 |
| TIMESTAMP | YYYY-MM-DD HH:MM:SS | 1970-01-01 00:00:01 UTC 到 2038-01-19 03:14:07 UTC |
SQL Syntax
CATEGORY
| 分类 | 全称 | 说明 |
|---|---|---|
| DDL | Data Definition Language | 定义数据库对象(数据库,表,字段) |
| DML | Data Manipulation Language | 对数据表中的数据进行增删改 |
| DQL | Data Query Language | 查询数据库中表的记录 |
| DCL | Data Control Language | 创建数据库用户,控制数据库的访问权限 |
| TCL | Transaction Control Language | 用于保存或恢复对数据库对象执行的操作 |
DML 语句和 DDL 语句区别:DML 是数据库操作语言(Data Manipulation Language)的缩写,是指对数据库中表记录的操作,主要包括表记录的插入、更新、删除和查询,是开发人员日常使用最频繁的操作。DDL (Data Definition Language)是数据定义语言的缩写,简单来说,就是对数据库内部的对象进行创建、删除、修改的操作语言。它和 DML 语言的最大区别是 DML 只是对表内部数据的操作,而不涉及到表的定义、结构的修改,更不会涉及到其他对象。DDL 语句更多的被数据库管理员(DBA)所使用,一般的开发人员很少使用。另外,由于 select 不会对表进行破坏,所以有的地方也会把 select 单独区分开叫做数据库查询语言 DQL(Data Query Language)。## 执行速度不同
节选自 JavaGuide——SnailClimb
DDL
Database Manipulation
- 创建:
CREATE DATABASE <DATABASE_NAME>; - 删除:
DROP DATABASE <DATABASE_NAME>; - 查看:
SHOW DATABASES; - 使用:
USE <DATABASE_NAME>; - 查询当前数据库:
SELECT DATABASE();
Table Manipulation
- 删除:
DROP TABLE <TABLE_NAME>; - 创建:
CREATE TABLE <TABLE_NAME> (field_name field_type, ...); - 重命名:
ALTER TABLE <TABLE_NAME> RENAME TO <NEW_TABLE_NAME>; - 删除重建:
TRUNCATE TABLE <TABLE_NAME>; - 描述表结构:
DESC <TABLE_NAME>; - 查询当前数据库中的表:
SHOW TABLES; - 查看表的创建语句:
SHOW CREATE TABLE <TABLE_NAME>;
1
2
3
4
5
6
7
8
CREATE TABLE student(
id int,
name varchar(32),
age int
);
DESC student;
ALTER TABLE student RENAME TO student_info;
DROP student_info;- Add/Modify Field:
ALETR TABLE <TABLE_NAME> <ADD|MODIFY> <FIELD_NAME> <FIELD_TYPE>; - Change Field:
ALTER TABLE <TABLE_NAME> CHANGE <FIELD_NAME> <NEW_FIELD_NAME> <FIELD_TYPE>; - Drop Field:
ALTER TABLE <TABLE_NAME> DROP <FIELD_NAME>;
1
2
3
4
-- Field Manipulation Examples
ALTER TABLE student ADD age int UNSIGNED;
ALTER TABLE student MODIFY age tinyint UNSIGNED;
ALTER TABLE student CHANGE nickname username tinyint UNSIGNED;DML
INSERT
基本的 INSERT 语句的语法如下:
1
INSERT INTO table_name (field1, field2, field3, ...) VALUES (value1, value2, value3, ...);例如,如果你有一个名为 users 的表,它有 id,name 和 email,gender 四个 field,你可以使用以下的 INSERT 语句来插入数据:
1
INSERT INTO users (id, name, email) VALUES (1, 'John Doe', '[email protected]');可以省略列的名称,但必须提供所有 field的值,并且顺序必须与表中的列的顺序相同:
1
INSERT INTO users VALUES (1, 'John Doe', '[email protected]','男');批量插入数据:
1
2
3
4
5
INSERT INTO users (id, name, email)
VALUES
(1, 'Alice', '[email protected]'),
(2, 'Bob', '[email protected]'),
(3, 'Charlie', '[email protected]');DELETE
1
2
3
DELETE FROM student; -- 删除表中所有数据
DELETE FROM student where id = 1; -- 删除id为1的数据
TRUNCATE TABLE student; -- 删除表中所有数据,但不删除表结构🪧drop,delete,truncate的区别:
DROP TABLEis aDDLcommand. It is used to delete a table and free space associated with the table. It also deletes the table structure.TRUNCATE TABLEis aDDLcommand. It is used to delete all the rows from a table and free the space used by those rows. It does not generate any undo logs, so it is faster than the DELETE command. However, you CANNOT roll back a TRUNCATE operation. Also, TRUNCATE TABLE resets the identity of the table.DELETE FROMis aDMLcommand. It is used to delete all the rows from a table or certain rows that match a condition. It generates undo logs for every deleted row, so you CAN roll back a DELETE operation. It does not reset the identity of the table. DELETE FROM without a WHERE clause behaves like TRUNCATE TABLE.
PS:identity is a property of a column that is used to generate a sequence of numbers(id e.g.). The identity column is commonly used as a primary key.
可参考如下文章补充学习
UPDATE
1
2
UPDATE student SET age = 18; -- Note:affects all rows in the table.
UPDATE student SET age = 18 WHERE id = 1;DQL
OVERVIEW
数据查询语言(Data Query Language)用于从数据库中检索数据。
Sequence Of DQL
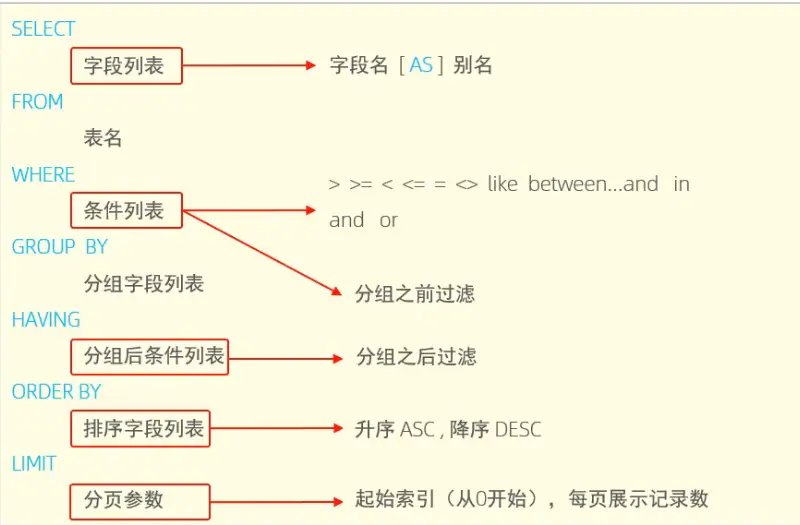
编写顺序: SELECT->FROM->WHERE->GROUP BY->HAVING->ORDER BY->LIMIT>
执行顺序: FROM->WHERE->GROUP BY->HAVING->SELECT->ORDER BY->LIMIT
练习
1
2
3
4
5
6
7
8
9
10
11
-- table name: emp
-- 1.查询年龄为20,21,22,23的女性员工信息
SELECT * FROM emp WHERE gender='女' && age IN (20,21,22,23);
-- 2.查询性别为男,并且年属于[20,40],名字为3个字的员工。
SELECT * FROM emp WHERE gender='男' && age BETWEEN 20 AND 40 && name LIKE '___';
-- 3.查询年龄小于60岁的男员工人数和女员工人数
SELECT gender,count(*) FROM emp GROUP BY gender
-- 4.查询所有年小于等于 35 员工的姓名和年龄,并对查询结果按年龄升序排序,如果年龄相同按入职时间降序排序
SELECT name,age,entrydate FROM emp WHERE age <= 35 ORDER BY age ASC,entrydate DESC;
-- 5.查询性别为男,且年龄属于[20,40]的前5个员工,并对查询结果按年龄升序排序,如果年龄相同按入职时间降序排序
SELECT name,age,entrydate FROM emp WHERE gender='男' && age BETWEEN 20 AND 40 ORDER BY age ASC,entrydate DESC LIMIT 5;基础查询
1
2
3
4
5
6
7
8
9
10
11
12
13
table: student
+-----+-------+-----------+------+
| Sid | Sname | Sage | Ssex |
+-----+-------+-----------+------+
| 01 | 赵雷 | 1/1/1990 | 男 |
| 02 | 钱电 | 21/12/1990| 男 |
| 03 | 孙风 | 20/5/1990 | 男 |
| 04 | 李云 | 6/8/1990 | 男 |
| 05 | 周梅 | 1/12/1991 | 女 |
| 06 | 吴兰 | 1/3/1992 | 女 |
| 07 | 郑竹 | 1/7/1989 | 女 |
| 08 | 王菊 | 20/1/1990 | 女 |
+-----+-------+-----------+------+Basic Syntax
- 查询指定字段
SELECT field1, field2, ... FROM table_name; - 查询所有字段
SELECT * FROM table_name; - 指定条件查询
SELECT field1, field2, ... FROM table_name WHERE condition; - 查询结果去重
SELECT DISTINCT field1, field2, ... FROM table_name;
Condition Syntax
List of Comparison Operators
=, !=,<>, < <=, >, >= 🪧Note:<> is the same as !=BETWEEN ... AND ...IN(...)LIKE 🪧Note:pattern matching,placeholders:%,_IS NULL,IS NOT NULL
List of Logical Operators
AND,&&,OR,||,NOT,!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
SELECT * FROM student; -- 查询表中所有field数据
SELECT id,name FROM student; -- 查询表中指定field的数据
SELECT * FROM student WHERE id = 1 && age <=30; -- && 可以用 AND 代替
SELECT * FROM student WHERE id = 1 || age <=30; -- || 可以用 OR 代替
SELECT * FROM student WHERE Sid BETWEEN 01 AND 20; -- BETWEEN 用于范围查询[01,20]
SELECT * FROM student WHERE Sid IN (01,02,03); -- IN 用于范围查询
SELECT DISTINCT Ssex FROM student; -- DISTINCT 用于去重
SELECT * FROM student WHERE enligh IS NOT NULL; -- IS NULL 用于判断是否为空
-- =================================
-- * LIKE *
-- =================================
SELECT * FROM student WHERE Sname LIKE '赵%'; -- % 多个任意字符
SELECT * FROM student WHERE Sname LIKE '赵_'; -- _ 单个任意字符
SELECT * FROM student WHERE Sname LIKE '赵__'; -- __ 两个任意字符
SELECT * FROM student WHERE Sname LIKE '%子%'; -- Sname中包含子的recordExamples
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
-- example 1
SELECT Sid,Sname FROM student WHERE Ssex='男';
+-----+-------+
| Sid | Sname |
+-----+-------+
| 01 | 赵雷 |
| 02 | 钱电 |
| 03 | 孙风 |
| 04 | 李云 |
+-----+-------+
-- example 2
SELECT DISTINCT Ssex FROM student;
+------+
| Ssex |
+------+
| 男 |
| 女 |
+------+聚合函数
聚合函数(Aggregate Functions)用于计算表中列的值(如果为 NULL,则不参与计算),返回一个单一的值。常用的聚合函数有:
AVG():返回某列的平均值COUNT():返回某列的行数MAX():返回某列的最大值MIN():返回某列的最小值SUM():返回某列值之和
COUNT(*)表示计算所有行的数量,包括 NULL 值COUNT(field)表示计算指定列的行数,不包括 NULL 值COUNT(DISTINCT field)表示计算指定列的不同值的数量,不包括 NULL 值
Examples
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
SELECT count(Sid) FROM student;
+------------+
| count(Sid) |
+------------+
| 8 |
+------------+
SELECT avg(Sage) FROM student;
+---------------+
| avg(Sage) |
+---------------+
| 19903121.3750 |
+---------------+
SELECT avg(Sage) FROM student WHERE Ssex='男';
+---------------+
| avg(Sage) |
+---------------+
| 19900662.0000 |
+---------------+分组查询
分组查询(Group By)用于结合聚合函数,根据一个或多个列对结果集进行分组。
Syntax:SELECT field1, field2, ... FROM table_name GROUP BY field1, field2, ... HAVE condition;
Difference between WHERE and HAVING
- 执行时机不同:
WHERE在数据分组前的 record 进行过滤,HAVING在数据分组后的 record 进行过滤
执行顺序:where -> aggregate -> having - 可选参数不同:
WHERE后面只能跟条件表达式,HAVING后面可以跟条件表达式和聚合函数
WHEREis used to filter records before any groupings take place.HAVINGis used to filter values after they have been grouped.
Examples
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
-- 查询男女生的max/min age;
SELECT Ssex,max(Sage),min(Sage) FROM student GROUP BY Ssex;
+------+------------+------------+
| Ssex | max(Sage) | min(Sage) |
+------+------------+------------+
| 男 | 1990-12-21 | 1990-01-01 |
| 女 | 1992-03-01 | 1989-07-01 |
+------+------------+------------+
-- 查询Sid>2的男女生的max/min age
SELECT Ssex,max(Sage),min(Sage) from student WHERE Sid>2 GROUP BY Ssex;
+------+------------+------------+
| Ssex | max(Sage) | min(Sage) |
+------+------------+------------+
| 男 | 1990-08-06 | 1990-05-20 |
| 女 | 1992-03-01 | 1989-07-01 |
+------+------------+------------+
-- 查询男女生的max/min age,分组结果只显示为Ssex=男的record
SELECT Ssex,max(Sage),min(Sage) from student GROUP BY Ssex HAVING Ssex='男';
+------+------------+------------+
| Ssex | max(Sage) | min(Sage) |
+------+------------+------------+
| 男 | 1990-12-21 | 1990-01-01 |
+------+------------+------------+
-- 查询年龄 < 45 的employee,并根据workaddress分组,显示分组结果中address_count>3的分组
SELECT workaddress,count(*) AS address_count FROM employee WHERE age < 45 GROUP BY workaddress HAVING address_count>3;
+--------------+----------------+
| workaddress | address_count |
+--------------+----------------+
| Beijing | 4 |
| Shanghai | 5 |
+--------------+----------------+排序查询
Syntax SELECT field1, field2, ... FROM table_name ORDER BY field1 [ASC|DESC], field2 [ASC|DESC], ...;
- ASC: ascending order 升序
- DESC: descending order 降序
- 如果有多个排序条件,则当前边的条件值一样时,才会判断第二条件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
SELECT * FROM student ORDER BY Sage ASC;
+-----+-------+------------+------+
| Sid | Sname | Sage | Ssex |
+-----+-------+------------+------+
| 07 | 郑竹 | 1989-07-01 | 女 |
| 01 | 赵雷 | 1990-01-01 | 男 |
| 08 | 王菊 | 1990-01-20 | 女 |
| 03 | 孙风 | 1990-05-20 | 男 |
| 04 | 李云 | 1990-08-06 | 男 |
| 02 | 钱电 | 1990-12-21 | 男 |
| 05 | 周梅 | 1991-12-01 | 女 |
| 06 | 吴兰 | 1992-03-01 | 女 |
+-----+-------+------------+------+
-- 按照age升序排序,如果age相同,则再按照entrydate降序排序
SELECT * FROM emp ORDER BY age ASC,entrydate DESC;分页查询
Syntax SELECT field1, field2, ... FROM table_name LIMIT offset, count;offset表示偏移量,count表示查询的记录数offset = (pageNo - 1) * pageSize
分页查询属于 MySQL 的扩展语法,不是 SQL 标准语法,不同的数据库有不同的实现方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
SELECT * FROM student LIMIT 0,3; -- 第1页
SELECT * FROM student LIMIT 3,3; -- 第2页
SELECT * FROM student LIMIT 6,2; -- 第3页
+-----+-------+------------+------+
| Sid | Sname | Sage | Ssex |
+-----+-------+------------+------+
| 01 | 赵雷 | 1990-01-01 | 男 |
| 02 | 钱电 | 1990-12-21 | 男 |
| 03 | 孙风 | 1990-05-20 | 男 |
+-----+-------+------------+------+
3 rows in set (0.27 sec)
+-----+-------+------------+------+
| Sid | Sname | Sage | Ssex |
+-----+-------+------------+------+
| 04 | 李云 | 1990-08-06 | 男 |
| 05 | 周梅 | 1991-12-01 | 女 |
| 06 | 吴兰 | 1992-03-01 | 女 |
+-----+-------+------------+------+
3 rows in set (0.23 sec)
+-----+-------+------------+------+
| Sid | Sname | Sage | Ssex |
+-----+-------+------------+------+
| 07 | 郑竹 | 1989-07-01 | 女 |
| 08 | 王菊 | 1990-01-20 | 女 |
+-----+-------+------------+------+
2 rows in set (0.22 sec)DCL
用户管理
CREATE用于创建一个新的用户,并设置其密码ALTER用于修改一个已存在的用户的密码DROP用于删除一个已存在的用户
%:表示用户可以从任何主机连接到数据库localhost:表示用户只能从本地主机连接到数据库192.168.1.1:表示用户只能从指定的 IP 地址连接到数据库%.example.com:表示用户可以从 example.com 域名下的任何主机连接到数据库
1
2
3
4
CREATE USER 'Jason'@'xxx.xxx.x.x' IDENTIFIED BY 'password'; -- 可从指定主机连接到数据库
CREATE USER 'Jason'@'%' IDENTIFIED BY 'JasonPassword'; -- 可从任何主机连接到数据库
ALTER USER 'Jason'@'%' IDENTIFIED BY 'NewJasonPassword';
DROP USER 'username'@'host';权限管理
GRANT:用于授予用户数据库的访问权限REVOKE:用于撤销用户的数据库访问权限。例如:
1
2
3
4
-- 授予 user 在 database.table 上执行 SELECT,INSERT 和 DELETE 操作的权限。
GRANT SELECT, INSERT, DELETE ON database.table TO 'user'@'host';
-- 撤销了 user 在 database.table 上执行 INSERT 和 DELETE 操作的权限。
REVOKE INSERT, DELETE ON database.table FROM 'user'@'host';常用权限
ALL, ALL PRIVILEGES所有权限SELECT查询数据INSERT插入数据UPDATE修改数据DELETE删除数据ALTER修改表DROP删除数据库/表/视图CREATE创建数据库/表
DataBase Base_基础概念&SQL语法