

File System
文件系统概述
文件系统的功能
- 有效地管理文件的存储空间;
- 管理文件目录;
- 完成文件的读/写操作;
- 实现文件共享与保护;
- 为用户提供交互式命令接口和程序调用接口。
定义:操作系统中的各类文件、管理文件的软件,以及管理文件所涉及到的数据结构等信息的集合。
有少数实时操作系统没有文件系统功能,绝大多数操作系统都包含文件管理系统部分。
文件类型 File Type
1. 按用途分类
- 系统文件 这是指由系统软件构成的文件。大多数的系统文件只允许用户调用,但不允许用户去读,更不允许修改;有的系统文件不直接对用户开放。
- 用户文件 由用户的源代码、目标文件、可执行文件或数据等所构成的文件。
- 库文件 这是由标准子例程及常用的例程等所构成的文件。这类文件允许用户调用,但不允许修改。
2. 按文件中数据的形式分类
- 源文件:指由源程序和数据构成的文件
.c .cpp .java .py etc - 目标文件:指把源程序经过相应语言的编译程序编译过,但尚未经过链接程序链接的目标代码所构成的文件。它属于二进制文件
.obj, .o - 可执行文件:指把编译后所产生的目标代码再经过链接程序链接后所形成的文件
.exe,.dlllinux 的可执行文件一般没有后缀,但文件权限通常设置为可执行
3. 按存取控制属性分类
根据系统管理员或用户所规定的存取控制属性
- 只执行文件
x - 只读文件
r - 读写文件
rw
4. 按组织形式和处理方式分类
- 普通文件:由 ASCII 码或二进制码组成的字符文件。一般用户建立的源程序文件、数据文件、目标代码文件及操作系统自身代码文件、库文件、实用程序文件等都是普通文件,它们通常存储在外存储设备上。
- 目录文件:由文件目录组成的,用来管理和实现文件系统功能的系统文件,通过目录文件可以对其它文件的信息进行检索。由于目录文件也是由字符序列构成,因此对其可进行与普通文件一样的种种文件操作。
- 特殊文件:特指系统中的各类 I/O 设备。为了便于统一管理,linux 系统将所有 IO 设备都视为文件,按文件方式提供给用户使用
文件系统模型 File System Model
模型的层次结构
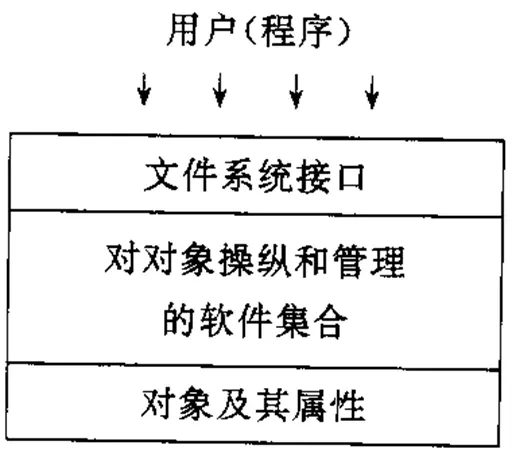
- 对象及其属性
文件管理系统管理的对象有:- 文件。它作为文件管理的直接对象。
- 目录。为了方便用户对文件的存取和检索,在文件系统中必须配置目录。对目录的组织和管理是方便用户和提高对文件存取速度的关键。
- 磁盘(磁带)存储空间。 文件和目录必定占用存储空间,对这部分空间的有效管理,不仅能提高外存的利用率,而且能提高对文件的存取速度。
- 对对象操纵和管理的软件集合
这是文件管理系统的核心部分。文件系统的功能大多是在这一层实现的,其中包括:- 对文件存储空间的管理
- 对文件目录的管理
- 用于将文件的逻辑地址转换为物理地址的机制
- 对文件读和写的管理
- 对文件的共享与保护等功能
- 文件系统的接口
为方便用户使用文件系统,文件系统通常向用户提供两种类型的接口:- 命令接口。这是指作为用户与文件系统交互的接口。 用户可通过键盘终端键入命令,取得文件系统的服务。
- 程序接口。这是指作为用户程序与文件系统的接口。 用户程序可通过系统调用来取得文件系统的服务。
文件操作示例
用户通过文件系统提供的系统调用实施对文件的操作。
- 最基本的文件操作有:创建文件、删除文件。读文件、写文件、截断文件和设置文件的读/写位置。
- 文件的“打开”和“关闭”操作:所谓“打开”,是指系统将指名文件的属性(包括该文件在外存上的物理位置)从外存拷贝到内存打开文件表的一个表目中,并将该表目的编号(或称为索引)返回给用户。 利用“关闭”(close)系统调用来关闭此文件,OS 将会把该文件从打开文件表中的表目上删除掉。
- 其它文件操作:对文件属性的操作,改变文件名、改变文件的拥有者,查询文件的状态等;
- open:打开一个文件,并指定访问该文件的方式,调用成功后返回一个文件描述符。
- creat:打开一个文件,如果该文件不存在,则创建它,调用成功后返回一个文件描述符。
- close:关闭文件,进程对文件所加的锁全都被释放。
- read:从文件描述符对应的文件中读取数据,调用成功后返回读出的字节数。
- write:向文件描述符对应的文件中写入数据,调用成功后返回写入的字节数。
文件的物理结构
文件是由一系列的记录组成的。
对于任何一个文件,都存在着以下两种形式的结构:
- 文件的逻辑结构:从用户观点出发所观察到的文件组织形式
- 文件的物理结构:指文件在外存上的存储组织形式
从逻辑组织的角度看,文件由若干记录构成;
从物理组织的角度看,文件由若干数据块组成.
操作系统或文件管理系统负责为文件分配和管理数据块。
如何划分磁盘空间?
如何为一个新建文件分配空间?
如何为一个已存在的文件增加存储空间?
用什么数据结构记载文件已分配到的数据块和空闲数据块?
文件的物理组织—存储空间的管理
在为文件分配外存空间时所要考虑的主要问题是:怎样才能有效地利用外存空间和如何提高对文件的访问速度。
目前,常用的外存分配方法有:
- 连续分配
- 链接分配
- 索引分配
连续分配 Continuous Allocation
连续分配(Continuous Allocation)要求为每一个文件分配一组相邻接的盘块。一组盘块的地址定义了磁盘上的一段线性地址。
把逻辑文件中的数据顺序地存储到物理上邻接的各个数据块中,这样形成的物理文件可以进行顺序存取。
文件目录中为每个文件建立一个表项,其中记载文件的第一个数据块地址及文件长度。
对于顺序文件,连续读/写多个数据块内容时,性能较好。
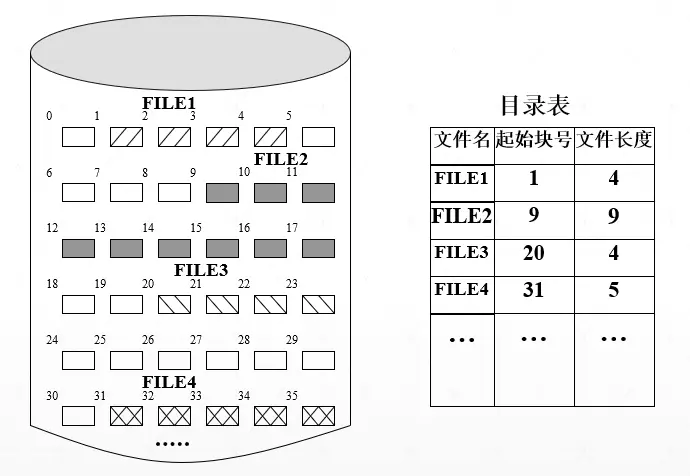
- 顺序访问容易。能很快检索文件中的一个数据块。例如,如果一个文件的第一个数据块的序号为 x,需要检索文件的第 y 块,则该数据块在外存中的位置为 x+y-1。
- 顺序访问在处理大量连续数据(如视频和音频流)时非常有效。磁头移动距离短,效率最高
- 要求有连续的存储空间。该分配方案可能会导致磁盘碎片,严重降低外存空间的利用率。解决方法之一,系统定期或不定期采用紧凑技术,将小分区合并为大的、连续分区,将文件占用空间合并在一起。
- 必须事先知道文件的长度。空间利用率不高;不利于文件尺寸的动态增长。
链接分配 Linked Allocation
连续分配的文件分区太大,不利于存储空间的有效利用。
如果在将一个逻辑文件存储到外存上时,可以考虑将文件装到多个离散的盘块中。
链接文件:采用链接分配方式时,可通过在每个盘块上的链接指针,将同属于一个文件的多个离散的盘块链接成一个链表,把这样形成的物理文件称为链接文件。
隐式链接 Implicit Linking
在采用隐式链接分配方式时,在文件目录的每个目录项中,都须含有指向链接文件第一个盘块和最后一个盘块的指针。每个盘块中都含有一个指向下一个盘块的指针。
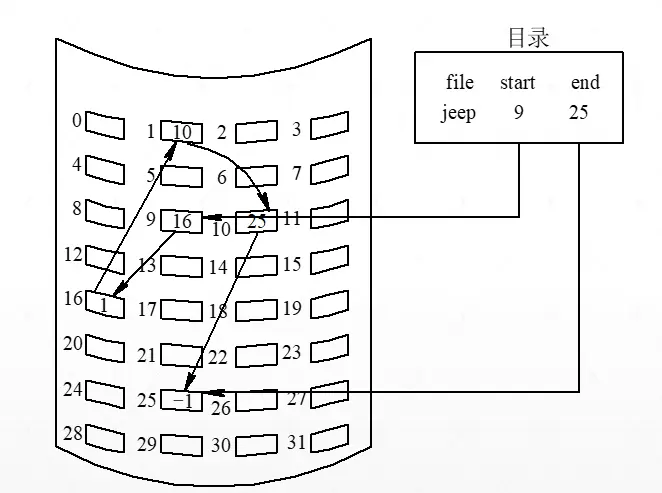
隐式链接分配方式的主要问题在于:它只适合于顺序访问,它对随机访问是极其低效的。
如果要访问文件所在的第 i 个盘块,则必须先读出文件的第一个盘块,然后顺序地查找直至第 i 块。
为了提高检索速度和减小指针所占用的存储空间,可以将几个盘块组成一个簇(cluster)。
比如,一个簇可包含 4 个盘块,在进行盘块分配时,是以簇为单位进行的。在链接文件中的每个元素也是以簇为单位的。
这减少了查找时间和指针所占空间,但增大了内部碎片,同时这种改进也是非常有限的。
显式链接 Explicit Linking
这是指把用于链接文件各物理块的指针,显式地存放在内存的一张链接表中。
整个磁盘仅设置一张文件分配表 FAT(File Allocation Table)
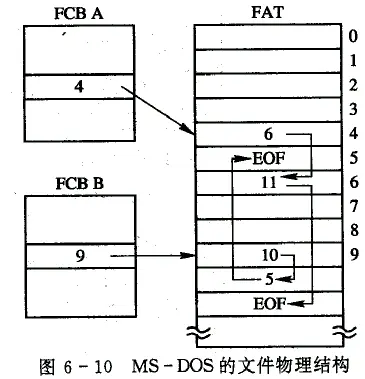
在该表中,凡是属于某一文件的第一个盘块号,均作为文件地址被填入相应文件的 FCB (File Control Block)的“物理地址”字段中。
查找记录的过程是在内存中进行的,因而不仅显著地提高了检索速度,而且大大减少了访问磁盘的次数。
由于分配给文件的所有盘块号都放在该表中,故把该表称为文件分配表 FAT (File Allocation Table)。
链接分配方式虽然解决了连续分配方式所存在的问题, 但又出现了另外两个问题, 即:
(1) 不能支持高效的直接存取。要对一个较大的文件进行直接存取,须首先在 FAT 中顺序地查找许多盘块号。
(2) FAT 需占用较大的内存空间。由于一个文件所占用盘块的盘块号是随机地分布在 FAT 中的,因而只有将整个 FAT 调入内存,才能保证在 FAT 中找到一个文件的所有盘块号。
NTFS (New Technology File System)
NTFS 是 Microsoft 在 Windows NT 3.1 中引入的文件系统,它提供了比 FAT 更高级的特性和性能。在 NTFS 中,文件的存储和链接方式与 FAT 有所不同。NTFS 使用了一种叫做 B+ 树的数据结构来存储文件和目录的信息。每个文件或目录在 NTFS 中都有一个叫做 MFT (Master File Table) 记录。MFT 记录包含了文件的所有信息,包括其属性、位置、大小等。对于较小的文件,其数据可能直接存储在 MFT 记录中。对于较大的文件,MFT 记录会包含一个指向文件数据块的指针列表。
总的来说,FAT 和 NTFS 在链接文件数据方面使用了不同的数据结构和算法。FAT 使用了相对简单的链表结构,而 NTFS 使用了更复杂但也更高效的 B+ 树结构。
索引分配 Indexed Allocation
单级索引分配 Single-level Indexing
索引分配能解决连续分配和链接分配存在的诸多问题。
原理:为每个文件分配一个索引块(表),再把分配给该文件的所有盘块号都记录在该索引块中,因而该索引块就是一个含有许多盘块号的数组。
在建立一个文件时,只需在为之建立的目录项中填上指向该索引块的指针。
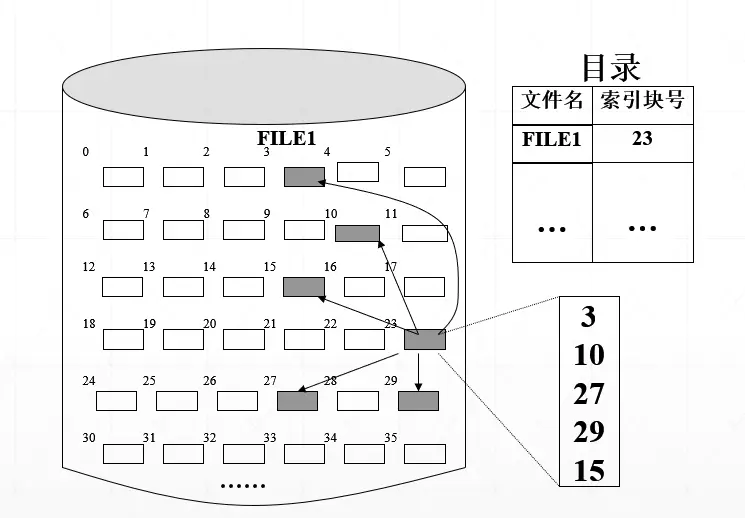
索引分配方式支持直接访问。当要读文件的第 i 个盘块时,可以方便地直接从索引块中找到第 i 个盘块的盘块号;
基于数据块的分区能消除外部碎片
大文件索引项较多,可能使一个数据块容纳不了一个文件的所有分区的索引。索引块可能要花费较多的外存空间。每当建立一个文件时,便须为之分配一个专门的索引块,将分配给该文件的所有盘块号记录于其中。对于小文件如果采用这种方式,索引块的利用率将是极低的。
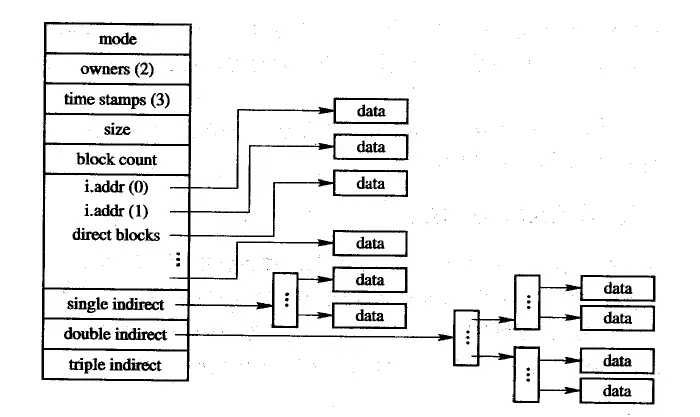
两级索引分配 Two-level Indexing
当文件太大,其一级索引块太多时,应为这些索引块再建立一级索引,形成两级索引分配方式。
即系统再分配一个索引块,作为第一级索引的索引块,将第一块、第二块……等索引块的盘块号填入到此索引表中
文件存储空间的管理
文件管理要解决的重要问题之一是如何为新创建的文件分配存储空间。
存储空间的基本分配单位是磁盘块。
其分配方法与内存的分配有许多相似之处,即同样可采取连续分配方式或离散分配方式。
系统应为分配存储空间而设置相应的数据结构;其次,系统应提供对存储空间进行分配和回收的手段。
文件存储空间的管理方法包括:
- 空闲分区表
- 空闲链表法
- 位示图
- 成组链接法
空闲表法 Free Space Table
空闲表法属于连续分配方式,它为每个文件分配一块连续的存储空间,即系统也为外存上的所有空闲区建立一张空闲表,每个空闲区对应于一个空闲表项,其中包括表项序号、该空闲区的第一个盘块号、该区的空闲盘块数等信息。表项序号 空闲区起始盘块号 空闲盘块数 1 2 4 2 9 3 3 15 5 4 … …
Steps
- 为文件分配存储空间时,首先顺序查找空闲分区表中的各个表项,直至找到第一个大小适合的空闲分区。
- 可以采用首次适应分配算法、最佳适应分配算法等。
- 然后,将该分区分配给文件,同时修改空闲分区表,删除相应表项。
- 当删除文件释放出空间时,系统回收其存储空间,合并相邻空闲分区.
对交换分区一般都采用连续分配方式。
对于文件系统,当文件较小(1 ~ 4 个盘块)时,仍采用连续分配方式,为文件分配相邻接的几个盘块;
当文件较大时,便采用离散分配方式。
实现简单。对于最佳适应分配算法,可以将各空闲分区按照(长度)从小到大的顺序进行排列,再利用有效的查找算法,能很快找到需要大小的空闲分区
当存储空间中的空闲分区分布较分散且数量较多时,空闲分区表将会很大。需要很大的内存空间,会降低空闲分区表的检索速度。
空闲链表法 Linked Free Space List
用专门的空闲分区表登记空闲分区信息会浪费一定的存储空间,而且不适合登记分散且数目很多的空闲分区,不利于基于存储块的链接文件和索引文件的存储空间分配。
空闲链表法是将所有空闲盘区拉成一条空闲链。根据构成链所用基本元素的不同,可把链表分成两种形式:
- 空闲盘块链
- 空闲盘区链
空闲盘区链 Free Space List
将磁盘上的所有空闲空间,以盘块为单位拉成一条链。
当用户因创建文件而请求分配存储空间时,系统从链首开始,依次摘下适当数目的空闲盘块分配给用户。
当用户因删除文件而释放存储空间时,系统将回收的盘块依次插入空闲盘块链的末尾。
空闲盘块链 Free Block List
将磁盘上的所有空闲盘区(每个盘区可包含若干个盘块)拉成一条链。
在每个盘区上含有用于指示下一个空闲盘区的指针和能指明本盘区大小(盘块数)的信息。
分配盘区的方法与内存的动态分区分配类似,通常采用首次适应算法。
在回收盘区时,同样也要将回收区与相邻接的空闲盘区相合并。
为了提高对空闲盘区的检索速度,可以采用显式链接方法,亦即,在内存中为空闲盘区建立一张链表。
每个分区结点内容:起始盘块号、盘块数、指向下一个空闲盘区的指针。
用于分配和回收一个盘块的过程非常简单.
一段时间以后,可能会使空闲分区链表中包含太多小分区,使文件分配到的存储空间过分离散。
删除一个由许多离散小分区组成的文件时,将回收的小分区链接到空闲分区链表中需要很长时间。
若一个文件申请连续存储空间,则需要花费较长的时间查找相邻的空闲分区。
因此,这种空闲空间组织方法适合于非连续存储文件。
位示图 Bit Map
利用二进制位 0、1 表示存储空间中存储块的使用状态。例如规定空闲分区为 0,已分配分区为 1
磁盘上的所有盘块都有一个二进制位与之对应,这样,由所有盘块所对应的位构成一个集合,称为位示图。
通常可用 m × n 个位数来构成位示图,并使 m × n 等于磁盘的总块数。位示图也可描述为一个二维数组map[m][n]1 2 3 4 5 6 7 8 9 10 11 1 1 1 0 0 1 1 1 1 0 0 0 2 1 0 1 0 0 1 0 1 0 0 0 3 1 1 0 0 1 1 0 1 0 0 0 4 1 1 0 1 0 1 1 1 0 0 0 … … … … … … … … … … … …
Steps
申请盘块
(1) 顺序扫描位示图(m×n),从中找出一个或一组其值为0的二进制位。
(2) 将所找到的一个或一组二进制位转换成与之相应的盘块号。
假 找到的其值为0的二进制位位于位示图的第 i 行、第 j 列,则其相应的盘块号应按下式计算:
(3) 修改位示图,令 map[i,j]=1
回收盘块
(1) 将回收盘块的盘块号转换成位示图中的行号和列号。转换公式为:
(2) 修改位示图,令 map[i,j] =0
可以容易地找到一个或一组连续的空闲分区。例如,需要找到 8 个相邻接的空闲盘块,只需在位示图中找出 8 个其值连续为"0"的位即可。
BitMap 占据空间为 Disk Space(Byte) ÷ (Block Size × 8),对于容量较小的磁盘,位示图占用的空间会很小
对于一个 16GB 的磁盘,若数据块大小为 512 字节,则位示图大小为 4MB,大约需要占用 8000 个磁盘块的存储空间。
很难一次性将该位示图全部装入内存。即使内存足够大,可以存放全部或绝大部分位示图数据,搜索一个很大的位示图将会降低文件系统的性能。
尤其当磁盘空间快用完,剩下的空闲磁盘块很少时,文件系统的性能将严重降低
成组链接法 Grouping Linkage
将磁盘所有空闲盘块分组;
设置空闲盘块号栈,存放当前可用的一组空闲盘块的盘块号和栈中尚有的空闲盘块总数;
后一组的所有盘块号以及盘块总数登记在前一组的第一个盘块中……依次类推,组与组之间形成链接关系;
最后一组少登记一个盘块号,多登记一个空闲盘块链的结束标志。
空闲盘块的组织
- 空闲盘块号栈:用来存放当前可用的一组空闲盘块的盘块号(最多含 100 个号),以及栈中尚有的空闲盘块号数 N。顺便指出,N 还兼作栈顶指针用。例如,当 N=100 时,它指向 S.free(99)。由于栈是临界资源,每次只允许一个进程去访问,故系统为栈设置了一把锁。(只有这个是放在内存中的,其它是在磁盘上。)
- 文件区中的所有空闲盘块被分成若干个组,比如,将每 100 个盘块作为一组。假定盘上共有 10 000 个盘块,每块大小为 1 KB,其中第 201 ~ 7999 号盘块用于存放文件,即作为文件区,这样,该区的最末一组盘块号应为 7901 ~ 7999;次末组为 7801 ~ 7900……;第二组的盘块号为 301 ~ 400;第一组为 201 ~ 300,如上图右部所示。
- 将每一组含有的盘块总数 N 和该组所有的盘块号记入其前一组的第一个盘块(从后往前分组)的 S.free(0)~ S.free(99)中。
- 将第一组的盘块总数和所有的盘块号记入空闲盘块号栈中,作为当前可供分配的空闲盘块号。
- 最末一组只有 99 个盘块,其盘块号分别记入其前一组的 S.free(1) ~ S.free(99)中,而在 S.free(0)中则存放“0”,作为空闲盘块链的结束标志。(注:最后一组的盘块数应为 99,不应是 100,因为这是指可供使用的空闲盘块,其编号应为(1 ~ 99),0 号中放空闲盘块链的结尾标志。)
空闲盘块的分配与回收
- 当系统要为用户分配文件所需的盘块时,须调用盘块分配过程来完成。该过程首先检查空闲盘块号栈是否上锁,如未上锁,便从栈顶取出一空闲盘块号,将与之对应的盘块分配给用户,然后将栈顶指针下移一格。
- 若该盘块号已是栈底,即 S.free(0),这是当前栈中最后一个可分配的盘块号。由于在该盘块号所对应的盘块中记有下一组可用的盘块号,因此,须调用磁盘读过程,将栈底盘块号所对应盘块的内容读入栈中,作为新的盘块号栈的内容,并把原栈底对应的盘块分配出去(其中的有用数据已读入栈中)。然后,再分配一相应的缓冲区(作为该盘块的缓冲区)。最后,把栈中的空闲盘块数减 1 并返回。
- 在系统回收空闲盘块时,须调用盘块回收过程进行回收。它是将回收盘块的盘块号记入空闲盘块号栈的顶部,并执行空闲盘块数加 1 操作。当栈中空闲盘块号数目已达 100 时,表示栈已满,便将现有栈中的 100 个盘块号记入新回收的盘块中,再将其盘块号作为新栈底。
文件目录 File Directory
文件目录管理
文件控制块(FCB):用于描述和控制文件的数据结构。它包括:
- 基本信息:文件名、文件类型等;
- 地址信息:卷(存储文件的设备)、起始地址(起始物理地址)、文件长度(以字节、字或块为单位)等。
- 访问控制信息:文件所有者、访问信息(用户名和口令等)、合法操作等;
- 使用信息:创建时间、创建者身份、当前状态、最近修改时间、最近访问时间等。
- …
文件目录:文件控制块的有序集合。
对目录管理的要求如下:
- 实现“按名存取”。
- 提高对目录的检索速度。
- 文件共享。
- 允许文件重名。
目录项的两种组织方式:
- FCB 存储全部目录内容
- 存储部分目录信息,如文件名、索引节点指针等,其余部分保存在索引节点(i Node)。打开文件时将索引节点从磁盘读到内存中。
iNode(索引节点)是 Unix 和类 Unix 操作系统中的文件系统的一个重要概念。每个文件或目录在文件系统中都由一个 iNode 来表示。iNode 包含了关于文件系统对象(如普通文件、目录或者其他类型)的重要信息,包括:
- 文件大小
- 文件所有者和组
- 文件权限(读、写、执行)
- 文件创建、访问和修改的时间戳
- 文件的数据块的位置
iNode 并不包含文件名或文件的路径,这些信息是由目录文件维护的。目录文件包含了文件名到 iNode 的映射。这种设计允许在文件系统中实现一些复杂的功能,如硬链接和软链接。
需要注意的是,每个 iNode 都有一个唯一的 iNode 编号,这个编号在文件系统中用来唯一标识一个文件或目录。
目录文件及操作
目录文件:一个文件目录也被看做是一个文件,即目录文件。是多个文件的目录项构成的一种特殊文件。目录的操作包括
- 搜索目录
- 创建目录
- 删除目录
- 显示目录
- 修改目录
目录结构
单级目录结构
所有用户的全部文件目录保存在一张目录表中,每个文件的目录项占用一个表项。
简单,易于实现,能实现目录管理的基本功能——按名存取。
查找速度慢,不允许重名,不便于实现文件共享
dir_entry_1->file1dir_entry_1->file2...dir_entry_n->filen两级目录结构
主文件目录 MFD(Master File Directory)、用户文件目录 UFD(User File Directory)
一定程度解决了重名问题,提高了文件目录检索效率,能实现简单的文件共享
不便用户文件的逻辑分类;进一步解决重名、共享、检索效率等问题
MainFolder│├── User1│ ││ ├── file1│ ││ └── file2│├── User2│ ││ ├── file1│ ││ └── file2│└── User3 │ ├── file1 │ └── file2层次目录结构
多级目录/树形目录结构
- 目录结构:多级目录结构又称为树型目录结构,主目录在这里被称为根目录,把数据文件称为树叶,其它的目录均作为树的结点。
- 路径名:从树的根(即主目录)开始,把全部目录文件名与数据文件名,依次地用“/”连接起来,即构成该数据文件的路径名(path name)。
系统中的每一个文件都有惟一的路径名。 - 当前目录:为每个进程设置一个“当前目录”,又称为“工作目录”进程对各文件的访问都相对于“当前目录”而进行。
- 层次结构清晰,便于管理和保护
- 有利于文件分类
- 解决重名问题
- 提高文件检索速度
- 能进行存取权限的控制
查找一个文件按路径名逐层检查,由于每个文件都放在外存,多次访盘影响速度
目录查询技术
对目录进行查询的方式有两种:线性检索法和 Hash 方法:
- 线性检索法
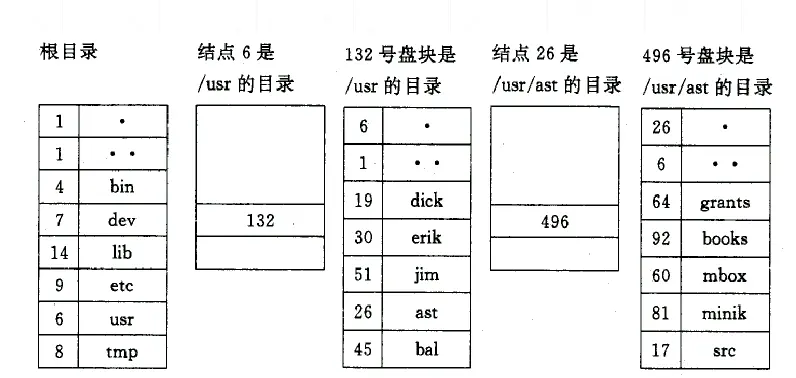
线性检索法又称为顺序检索法。- 在单级目录中,利用用户提供的文件名,用顺序查找法直接从文件目录中找到指名文件的目录项。
- 在树型目录中,用户提供的文件名是由多个文件分量名组成的路径名,此时须对多级目录进行查找。
- Hash 方法
- Hash 方法: 建立了一张 Hash 索引文件目录,系统利用用户提供的文件名并将它变换为文件目录的索引值,再利用该索引值到目录中去查找。
- Hash 方法将显著地提高检索速度。
- 在文件名中使用了通配符“* ”、“?”等,系统便无法利用 Hash 法检索目录,因此,需要利用线性查找法查找目录。
- 在进行文件名的转换时,不同的文件名可能转换为相同的 Hash 值,即 Hash 冲突。
- Steps
- 在利用 Hash 值查找目录时,如果目录表中相应的目录项是空的,则表示系统中并无指定文件。
- 如果目录项中的文件名与指定文件名相匹配,则表示该目录项正是所要寻找的文件所对应的目录项,故而可从中找到该文件所在的物理地址。
- 如果在目录表的相应目录项中的文件名与指定文件名并不匹配,则表示发生了“Hash 冲突”。
- 解决 Hash 冲突的方法 :将其 Hash 值再加上一个常数(该常数应与目录表的长度值互质),形成新的索引值,再返回到第一步重新开始查找。
使用一个和哈希表大小互质的步长,我们可以确保在经过足够多的步骤后,能够探测到哈希表中的每一个位置。这是因为两个互质的数的最小公倍数是它们的乘积,这意味着通过在原哈希值上加上步长,经过哈希表大小的步数后,我们可以覆盖到哈希表中的所有位置
文件共享和访问控制
文件共享的有效控制涉及两个方面:
- 同时存取(Simultaneous Access)
- 存取权限(Access Rights)
控制同时存取
- 允许多个用户同时读文件内容,但不允许同时修改,或同时读且修改文件内容。
- 共享用户之一修改文件内容时,可以将整个文件作为临界资源,锁定整个文件,不允许其他共享用户同时读或写文件。
- 也可以仅仅锁定指定的一条记录,允许其他共享用户读/写该文件的其它记录。后者的并发性能更好。
- 控制对文件的同时存取涉及进程的同步与互斥问题。
控制存取权限
控制授权用户以合法的方式访问文件,包括:
- 执行(Execution) — 用户可以装载并执行程序,但不允许拷贝程序内容。
- 读(Reading)— 允许用户读文件内容,包括拷贝和执行文件。某些系统严格地将浏览文件内容和拷贝权限分开,可以控制文件只能被浏览(显示),不能被拷贝。
- 追加(Appending)— 允许用户向文件添加数据,通常只能将数据添加到文件尾。但是,不能修改或删除文件内容。例如,超市收银员只能将新结帐的数据添加到文件中,不允许其修改或删除已有的数据。
- 更新(Updating)— 允许用户修改、删除、增加文件内容。包括创建文件、重写文件的全部或部分内容、移动文件的全部或部分数据等操作。
- 更改权限 (Changing protection) — 一般只有文件主才能更改共享该文件的其他用户对该文件的存取权限。有的系统允许文件主将更改文件存取权限赋予其他某个用户,但必须限制授权用户更改的权限范围。
- 删除 (Deletion) 允许用户删除文件
文件共享的实现
在树型结构的目录中,当有两个(或多个)用户要共享一个子目录或文件时,必须将共享文件或子目录链接到两个(或多个)用户的目录中,才能方便地找到该文件。此时该文件系统的目录结构已不再是树型结构,而是个有向非循环图。
实现文件共享的实质就是可以从不同地方打开同一个文件
打开文件的首要步骤就是找到文件的目录项,读取文件在外存的起始地址。
实现文件共享的方式:
- 利用链接目录项实现法
- 利用索引节点实现法
- 利用符号链实现法等
链接目录项实现文件共享
文件目录项中设置一个链接指针,用于指向共享文件的目录项。
- 访问文件时,根据链接指针内容找到共享文件的目录项,读取该目录项中文件起始位置等信息,操作该文件。
- 每当有用户(进程)共享文件时,共享文件目录项中的“共享计数”加 1;当用户不再共享该文件,撤消链接指针时,“共享计数”减 1。
- 只有当共享文件用户数为 1 时,才能删除共享文件。
/root│├── /dir1│ ││ ├── file1 (链接指针-> /root/dirShared/file)│├── /dir2│ ││ ├── file2 (链接指针-> /root/dirShared/file)│└── /dirShared │ └── file索引节点实现文件共享 Hard Link
也称为【硬连接】Hard Link
硬连接指通过索引节点来进行连接。在 Linux 的文件系统中,保存在磁盘分区中的文件不管是什么类型都给它分配一个编号,称为索引节点号(Inode Index)。在 Linux 中,多个文件名指向同一索引节点是存在的。一般这种连接就是硬连接。硬连接的作用是允许一个文件拥有多个有效路径名,这样用户就可以建立硬连接到重要文件,以防止“误删”的功能。其原因如上所述,因为对应该目录的索引节点有一个以上的连接。只删除一个连接并不影响索引节点本身和其它的连接,只有当最后一个连接被删除后,文件的数据块及目录的连接才会被释放。也就是说,文件真正删除的条件是与之相关的所有硬连接文件均被删除。
文件的物理地址及其它的文件属性等信息,不再是放在目录项中,而是放在索引结点中。在文件目录中只设置文件名及指向相应索引结点的指针。
- 由任何用户对文件进行 Append 操作或修改,所引起的相应结点内容的改变(例如,增加了新的盘块号和文件长度等),都是其他用户可见的,从而也就能提供给其他用户来共享。
- UNIX 操作系统的文件目录项中只包含文件名和指向索引节点的指针,文件的物理地址及其它说明信息保存在索引节点 iNode 中。
- 可以通过共享文件索引节点 iNode 来共享文件,即当用户需要共享文件时,在自己的文件目录中新建一个目录项,为共享文件命名(也可用原名),并将索引节点指针指向共享文件的索引节点。
/root│├── /dir1│ ││ ├── file1 (iNode指针-> iNode#123)│ ││ └── file3 (iNode指针-> iNode#124)│├── /dir2│ ││ ├── file2 (iNode指针-> iNode#123)│ ││ └── file4 (iNode指针-> iNode#125)│└── iNode Table │ ├── iNode#123 (物理地址, 文件属性, 共享计数: 2) │ ├── iNode#124 (物理地址, 文件属性, 共享计数: 1) │ ├── iNode#125 (物理地址, 文件属性, 共享计数: 1) │ └── ...在索引结点中还应有一个链接计数 count,用于表示链接到本索引结点(亦即文件)上的用户目录项的数目
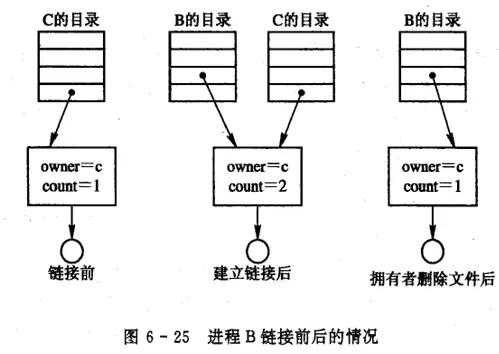
- 当用户 C 创建一个新文件时,他便是该文件的所有者,此时将 count 置 1。
- 当有用户 B 要共享此文件时,在用户 B 的目录中增加一目录项,并设置一指针指向该文件的索引结点,此时,文件主仍然是 C,count=2。
- 如果用户 C 不再需要此文件,是否能将此文件删除呢?
只能删除硬链接,但是不能删除里面的实际内容,当所有硬链接都删除后,才可以删除其内容和索引节点。
符号链接实现文件共享 Symbolic Link
为使 B 能共享 C 的一个文件 F,可以由系统创建一个 LINK 类型的新文件,也取名为 F 并将 F 写入 B 的目录中,以实现 B 的目录与文件 F 的链接;在新文件中只包含被创文件 F 的路径名。这样的链接方法被称为符号链接.
新文件中的路径名,则只被看作是符号链。当 B 要访问被链接的文件 F 且正要读 LINK 类新文件时,将被 OS 截获,OS 根据新文件中的路径名去读该文件,于是就实现了用户 B 对文件 F 的共享。
在利用符号链方式实现文件共享时,只有文件主才拥有指向其索引结点的指针,而共享该文件的其它用户,则只有该文件的路径名,并不拥有指向其索引结点的指针。
能连接任何机器上的文件。每增加一个连接,就增加一个文件名,各用户使用自己的名字去共享文件。
备份可能会产生多个拷贝。
符号连接(Symbolic Link),也叫软连接。软链接文件有类似于 Windows 的快捷方式。它实际上是一个特殊的文件。在符号连接中,文件实际上是一个文本文件,其中包含的有另一文件的位置信息。$ touch file$ ln file hard_link_f1 # 硬连接$ ln -s file sym_link_f1 # 软连接$ ls -li# 输出如下,硬链接的inode相同,count=2;软连接的inode不同,count=1total 0122779 -rw-r--r-- 2 gjx gjx 0 May 22 15:03 file122779 -rw-r--r-- 2 gjx gjx 0 May 22 15:03 hard_link_f1122781 lrwxrwxrwx 1 gjx gjx 4 May 22 15:04 sym_link_f1 - >file特性 硬链接 软链接 跨文件系统 ❌ 不支持 ✅ 支持 链接目录 ❌ 不支持 ✅ 支持 原文件删除后 链接仍可访问文件内容 链接失效(断链) 文件修改 所有硬链接同步修改 访问时修改会同步到原文件 文件属性 与原文件完全相同 有自己的属性(如权限) 文件大小 与原文件相同 等于路径字符串的长度 inode 编号 与原文件相同 不同于原文件
URL 实现文件共享
统一资源定位器 URL (Uniform Resource Locator)是 Internet 上用来链接超文本文件的一种方法。
它可以链接同一台计算机中的本地文件,也可链接 Internet 中任何主机上的远程文件。
一个完整的 URL 包括访问文件的方法(协议)、文件所在的主机域名、目录路径名和文件名几部份。例如file:///C:/Users/YourName/Documents/file.txthttp://www.uestc.edu.cn/templates/index2k3/index.html
文件保护
不同对象允许实施的操作各不相同。例如,文件可施加读、写、执行等操作,信号量只能施加 wait()和signal()操作。
因此,系统为所有对象设置一个允许进程实施操作的操作集,任何对对象的操作必须符合操作集中的规定,防止未授权进程访问对象。