

Storage Management PartⅡ
基本分页存储管理方式 Paged Storage Management
Intro
前面介绍的分区存储管理,一般都要求把一个作业的地址空间装入到连续的存储区域内。因此,在动态分区的存储空间中,常常由于存在着一些不足以装入任何作业的小的分区而浪费掉部分存储资源,这就是所谓存储器的零头问题。
尽管采用“紧凑”技术可以解决这个问题,但要为移动大量信息花去不少处理机时间,代价较高。
如果我们能取消对其存储区域的连续性要求,必然会进一步提高主存空间的利用率,又无需为移动信息付出代价。
离散分配 即程序在内存中不一定连续存放
根据离散时的基本单位不同,可分为三种:
- 分页存储管理
- 分段存储管理
- 段页式存储管理
离散的基础
分页(Pages):将程序地址空间分页
分块(Frames):将内存空间分块
离散分配的体现
内存一块可以装入程序一页
连续的多个页不一定装入连续的多个块中
注:系统中页块的大小是不变的。
离散分配的优点
没有外零头。不受连续空间限制,每块都能分出去
仅有小于一个页面的内零头。由于进程的最后一页经常装不满一块而形成了不可利用的碎片,称之为“页内碎片”或称为“内零头”。
定义
- 页面/页 Page: 作业的逻辑地址空间被分割成固定大小的片,称为页面
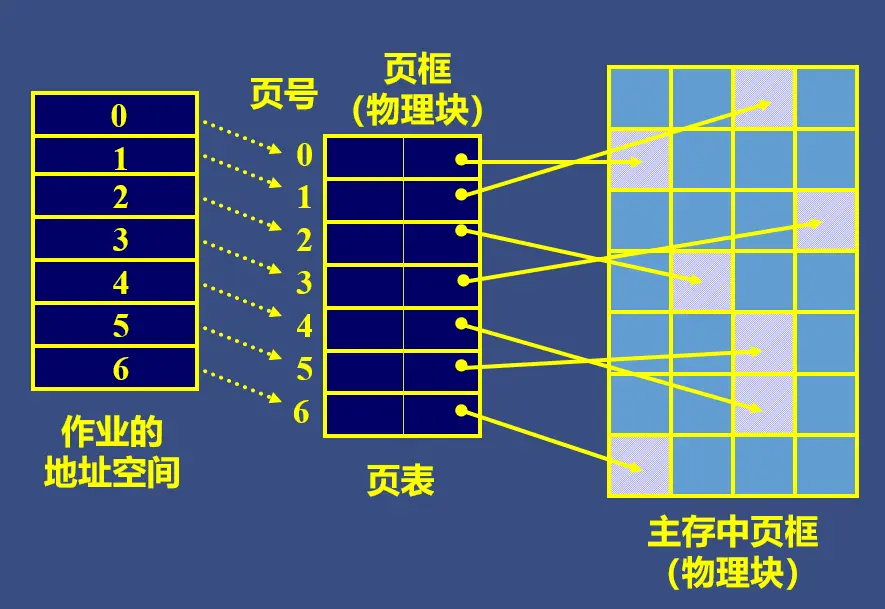
- 物理块/页框 Page Frame:内存空间也分成与页相同大小的若干存储块。在为进程分配存储空间时,总是以页框为单位。
Page 从 0 开始编号,页内地址是相对于 0 编址;
在进程调度时,必须把它所有的 Page 一次装入到主存的 Page Frame 内;如果当时 Page Frame 不足,则该进程必须等待,系统再调度另外的进程。(纯分页方式)
分页存储管理的基本方法
需解决的两个基本问题:
- 如何建立程序空间与主存空间的映射
- 如何进行地址变换(从程序逻辑地址到内存物理地址)
页面大小的选择
页面大小由机器的地址结构决定。某一机器只能采用一种大小的页面。页面的大小通常在 1KB~8KB 之间。
- 小页面
- 大页面
实现分页存储管理的数据结构
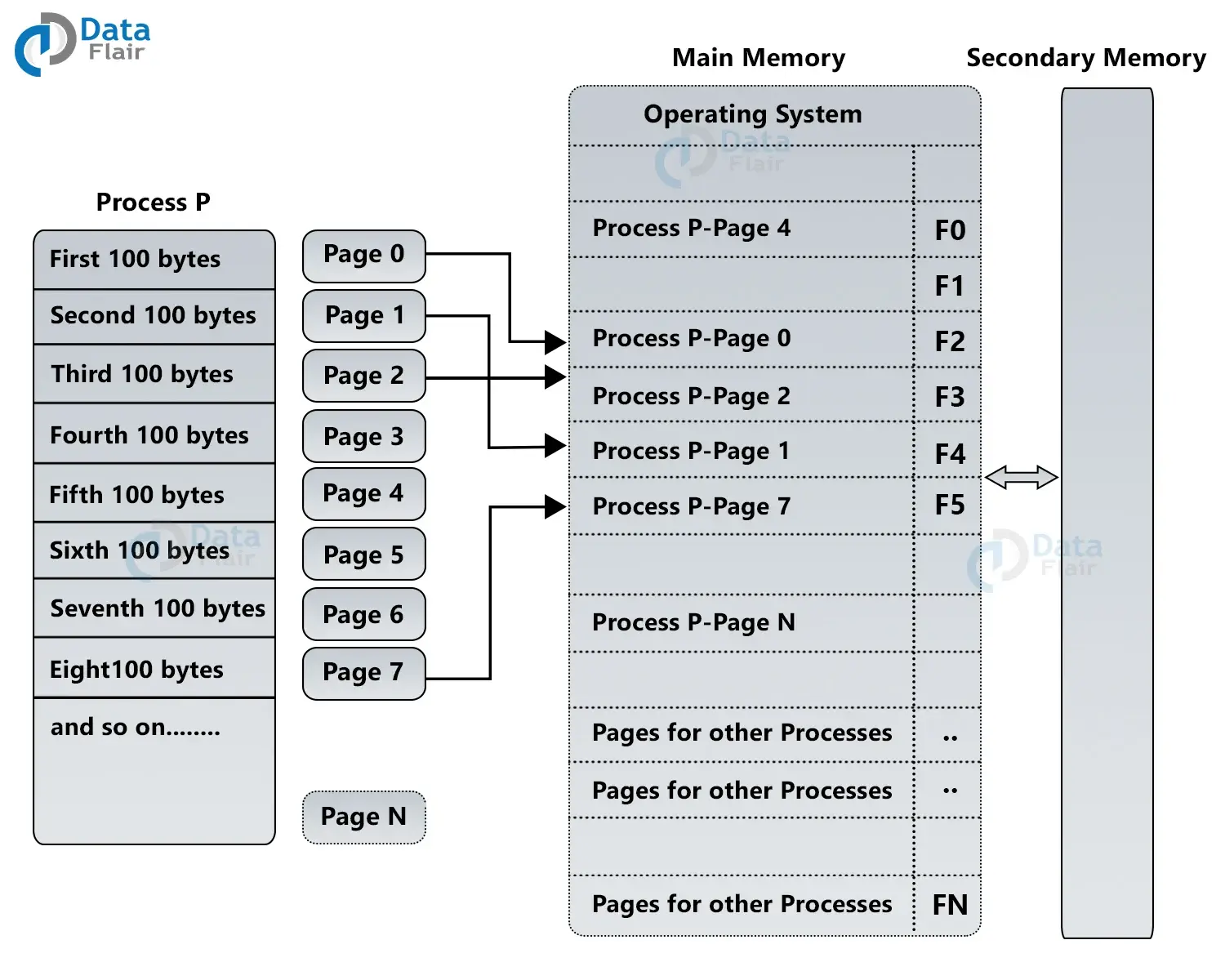
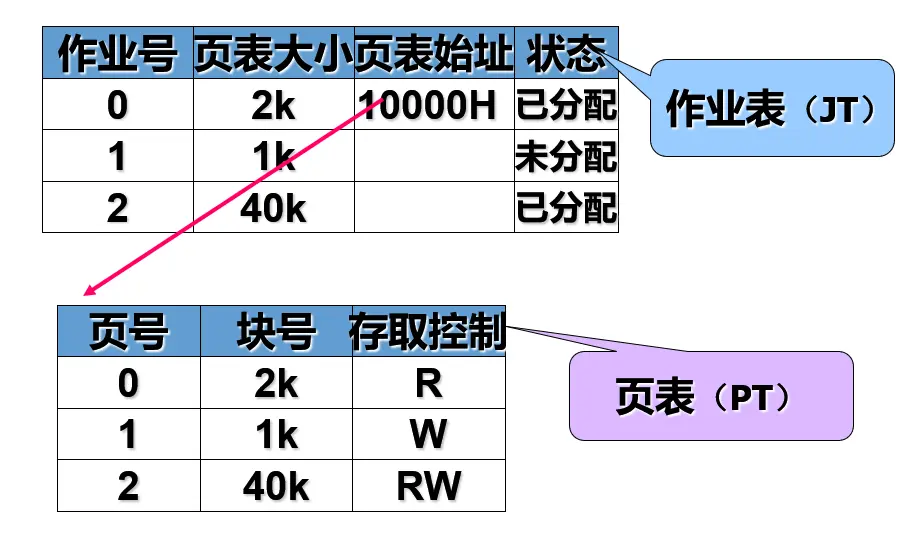
1)页表 Page Table:每个进程对应 1 个页表,由各个页表项(Page Table Entry,PTE)描述该进程的各页面在内存中对应的物理块号。
页表项中包括页号、物理块号、存储控制字段
状态位:这些位提供了关于页面的额外信息,例如该页面是否在内存中(有效位),是否可以写入(写保护位),是否被访问过(访问位),是否被修改过(脏位)等
注意:全部页表集中存放在主存的系统专用区中,只有系统有权访问页表,保证安全。
2)作业表 Job Table:整个系统 1 张,记录作业的页表情况,包含进程号、页表长度、页表始址等信息。
3)空闲块表:整个系统 1 张,记录主存当前空闲块。
某一作业被分成若干个 Page,每个 Page 可以去进程对应的页表中查找对应的物理块号,然后再去主存中找到对应的物理块(Page Frame)。
分页存储管理的逻辑地址表示
逻辑地址结构
地址空间为程序限定的空间。物理空间为内存限定空间。
在页式管理系统中将地址空间分成大小相同的页面 Page。将内存空间分成与页面相同大小的存储块 Page Frame。
分页存储管理方式中,任何一个逻辑地址都可转变为:页号+页内位移量。
页号、位移量的划分是由系统自动完成的,对用户是透明的。
设有一逻辑地址 A,页面大小为 L,则在分页存储管理方式中,它的地址被转换:
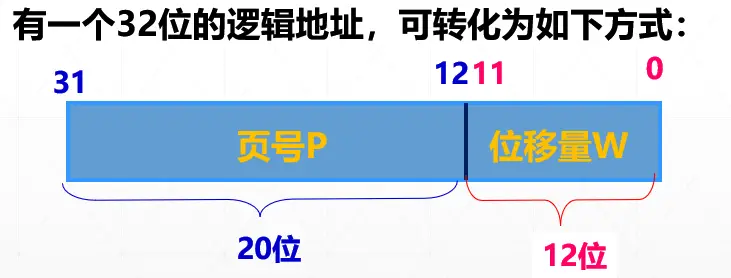
0 ~ 11 位表示页内位移量,则每页的大小为 212 = 4KB。
12 ~ 31 位表示页号,220=1M,即最多允许有 1M 个页面。
如有逻辑地址为:2170,页面大小为 1KB,则P=INT[2170/1024]=2;W=2170 MOD 1024=122
这个地址的变换通常由系统中的某些硬件完成。
Q
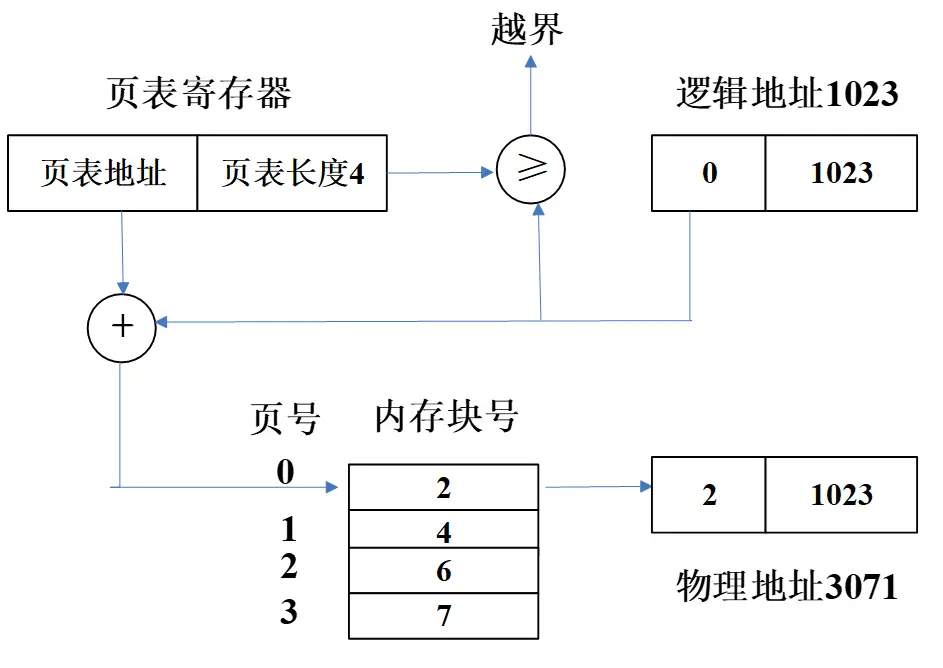
已知某分页系统,用户空间有 64 个页面,主存容量为 32KB,页面大小为 1KB,对一个 4 页大的作业,其 0、1、2、3 页分别被分配到主存的 2、4、6、7 块中。
(1)将十进制的逻辑地址 1023、2500、3500、4500 转换成物理地址?
(2)以十进制的逻辑地址 1023 为例画出地址变换过程图?
A
(1)
① 逻辑地址 1023:1023/1K,得页号为 0,页内地址为 1023,查页表找到对应的物理块号为 2,故物理地址为 2×1K+1023=3071
② 逻辑地址 2500:2500/1K,得页号为 2,页内地址为 452,查页表找到对应的物理块号为 6,故物理地址为 6×1K+452=6596
③ 逻辑地址 3500:3500/1K,得页号为 3,页内地址为 428,查页表找到对应的物理块号为 7,故物理地址为 7×1K+428=7596
④ 逻辑地址 4500:4500/1K,得页号为 4,页内地址为 404,因页号大于页表长度,故产生越界中断。
(2)
srcset="https://assets.vluv.space/UESTC/OS/Ch4-2StorageManagement/Ch4-2StorageManagement-2024-06-19-20-55-40.webp?w=500 500w, https://assets.vluv.space/UESTC/OS/Ch4-2StorageManagement/Ch4-2StorageManagement-2024-06-19-20-55-40.webp?w=1200 1200w, https://assets.vluv.space/UESTC/OS/Ch4-2StorageManagement/Ch4-2StorageManagement-2024-06-19-20-55-40.webp?w=2000 2000w, https://assets.vluv.space/UESTC/OS/Ch4-2StorageManagement/Ch4-2StorageManagement-2024-06-19-20-55-40.webp?w=3000 3000w"
loading="lazy" decoding="async"
style="width:100%; object-fit:cover; transition: opacity 0.3s; opacity:0;"
onload="this.style.opacity=1; this.parentElement.style.backgroundImage='none';"
alt=""></div>
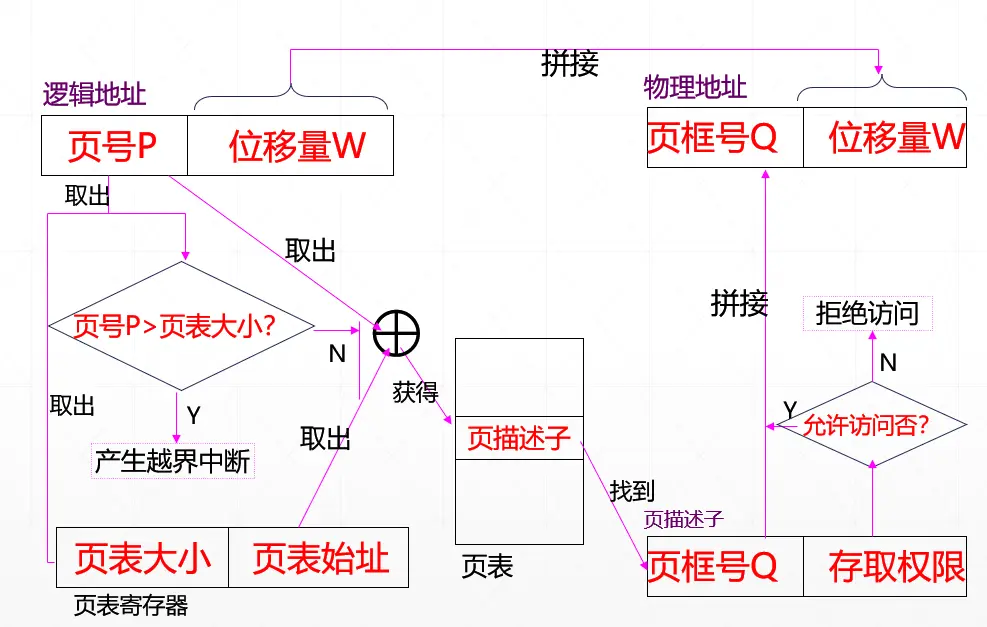
地址变换机构 Address Translation
地址变换机构的功能是将用户的逻辑地址转变为内存中的物理地址。
逻辑地址由页号和页内位移量组成。页(Page)的大小和内存物理块(Pageframe)的大小是相同的,所以页内位移量即为物理块内位移量。
关键是页号到物理块号的转换,由页表完成。
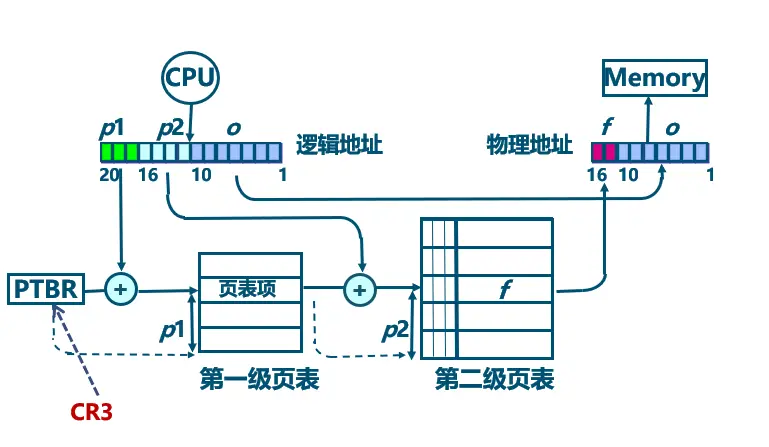
基本的地址变换机构
- 使用寄存器存放页表
速度快,成本高。特别对于大的系统,页表很长,不可能都用寄存器实现。 - 一般系统,将页表存储在内存中
设置一个页表寄存器(PTR),记录当前运行的进程的页表在内存中的始址和页表长度。(平时存于 PCB 中,要运行时才装入 PTR 中)
分页系统中的地址变换过程:
(1)根据逻辑地址,计算出页号和页内偏移量;
(2)从 PTR 中得到页表首址,然后检索页表,查找指定页面对应的页框号;
(3)用页框号乘以页面大小获得其对应的起始地址,并将其送入物理地址的高端。
(4)将页内偏移量送入物理地址低端,形成完整的物理地址。
具有快表的地址变换机构
分页系统中处理机每次存取指令或数据至少需要访问两次物理内存:
- 第一次访问页表,以得到物理地址
- 第二次访问物理地址,以得到数据。
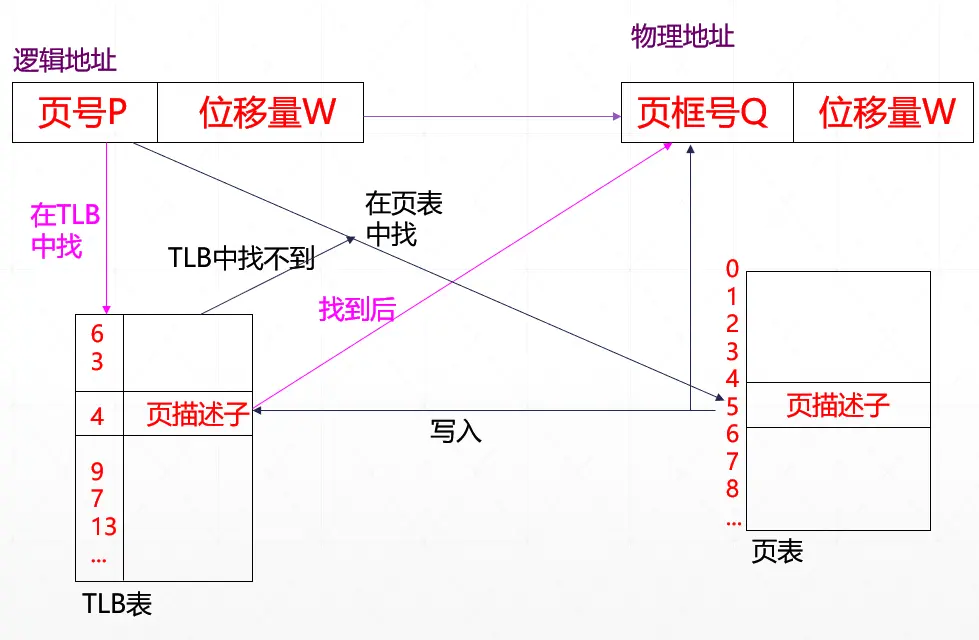
存取速度几乎降低了一倍,代价太高。为了提高地址变换速度,为进程页表设置一个专用的高速缓冲存储器,称为快表 TLB(Translation Lookaside Buffer)或联想存储器(Associative Memory) 。
Lookaside buffer 是一种硬件缓存机制,用于加速对特定类型数据的访问。这种缓存机制通常在 CPU 或其他硬件组件中实现,例如网络接口卡或硬盘控制器。
Lookaside buffer 的工作原理是将最近或最常访问的数据存储在一个快速访问的缓存中,以减少对慢速内存的访问。当 CPU 或其他硬件组件需要访问数据时,它们首先查看 lookaside buffer。如果所需的数据在缓存中,那么就可以快速地从缓存中获取,而无需访问慢速的内存。这被称为缓存命中。如果数据不在缓存中,那么就需要访问慢速的内存,并将数据放入缓存中以备后用。这被称为缓存未命中。
进程最近访问过的页面在不久的将来还可能被访问。快表的工作原理类似于系统中的数据高速缓存(cache),其中专门保存当前进程最近访问过的一组页表项。
快表地址转换过程
- 根据逻辑地址中的页号,查找快表中是否存在对应的页表项。
- 若快表中存在该表项,称为命中(hit),取出其中的页框号,加上页内偏移量,计算出物理地址。
- 若快表中不存在该页表项,称为命中失败,则再查找页表,找到逻辑地址中指定页号对应的页框号。同时,更新快表,将该表项插入快表中。并计算物理地址.
访问内存有效时间 EAT
访问内存有效时间 EAT(Effective Access Time):从进程发出指定逻辑地址的访问请求,经过地址变换,再到内存中找到对应的物理单元并取出数据,所花费的总时间。
如检索快表时间为 20 ns,访问内存为 100 ns。
若能在快表中检索到 CPU 给出的页号,则 CPU 存取一个数据共需 120 ns;否则,需要 220 ns 的时间。
如果不设置快表,CPU 存取一个数据需要 200 ns。快表(TLB)命中时效率会很高,未命中效率会降低,但平均后仍表现良好
为平均有效访问时间
为命中率
为快表访问时间, 为内存访问时间
两级和多级页表
问题引入
32 位逻辑地址空间,假设页面大小为 4KB(212),则 4GB(232)的逻辑地址空间将被划分成 220 个页面。
若采用一级页表,则该表将包含 1M(220)个页表项。若按字节寻址,一个页表项占 4B,则一级页表需要占用 4MB(222)内存空间。不可能将 4MB 的页表保存在一个连续区中。
那么,如何处理大页表的存储与检索呢?
可以采用这样两个方法来解决这一问题:
① 采用离散分配方式来解决难以找到一块连续的大内存空间的问题,(即引入两级页表);
② 只将当前需要的部分页表项调入内存, 其余的页表项仍驻留在磁盘上,需要时再调入。
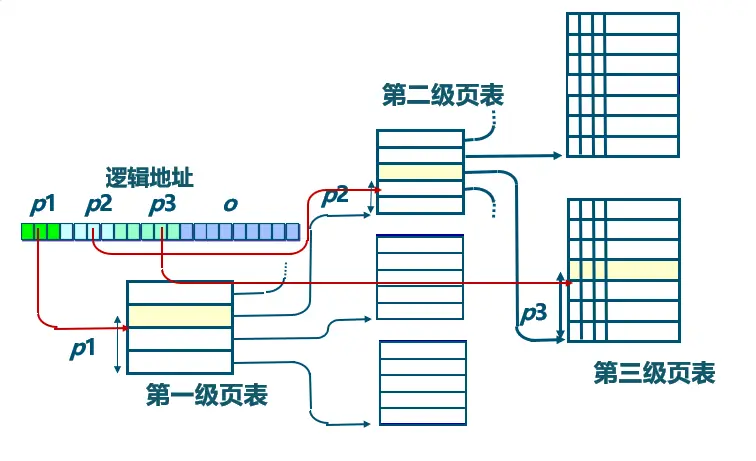
两级页表
对于要求连续的内存空间来存放页表的问题:
- 可将页表进行分页,并离散地将各个页面分别存放在不同的物理块中,
- 同样也要为离散分配的页表再建立一张页表,称为外层页表(Outer Page Table),在每个页表项中记录了页表分页的物理块号。
对于 4GB(
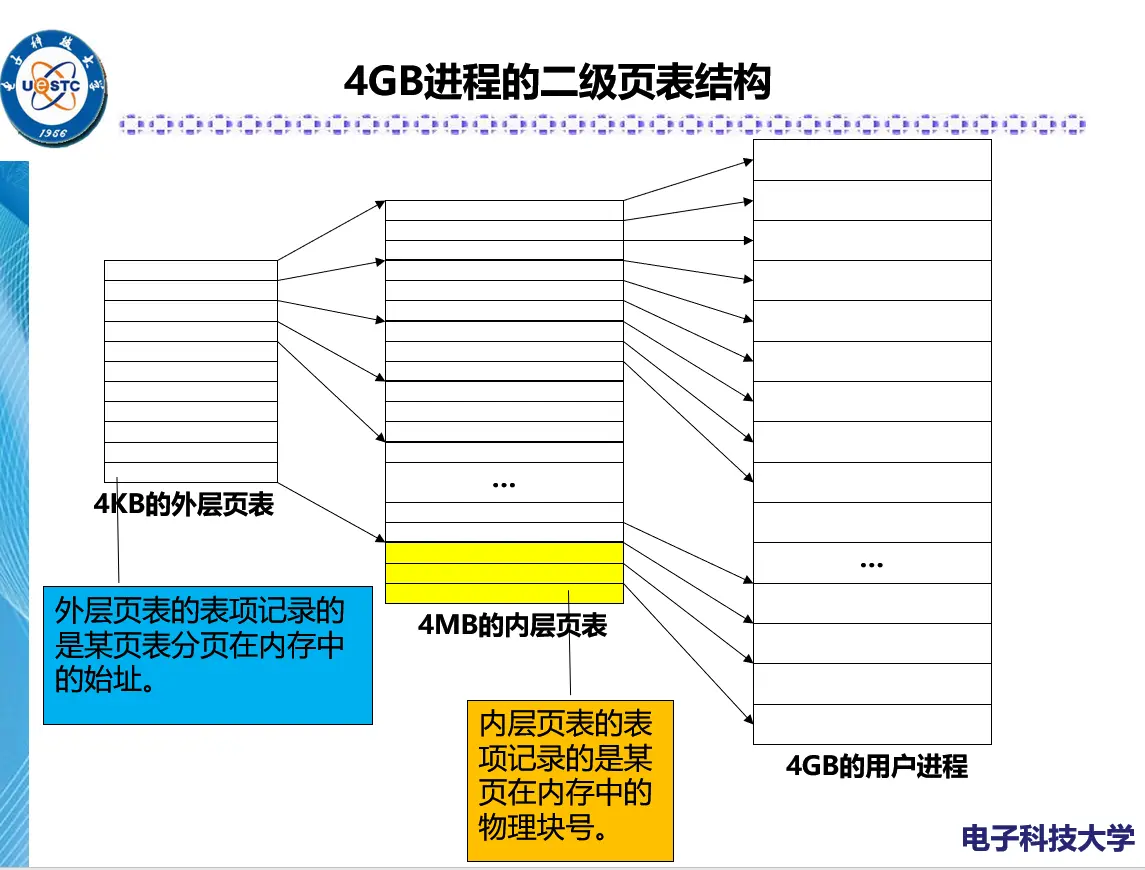
- 页面大小 4KB,故 32 位逻辑地址中要用 12 位表示页内偏移量。
- 4GB 的逻辑地址空间被分成
- 外层页表的表项记录的是某页在内存中的物理块号。外层页表个数为
- 前 10 位表示外层页表的页号,后 10 位表示内层页表的页号,最后 12 位表示页内偏移量。
变换机构:先在外层页表寄存器中找到外层页表的起始地址,根据逻辑地址中的外层页号找到对应的内层页表的起始地址,再根据逻辑地址中的内层页号找到对应的物理块号。
利用离散分配方法实现的两级页表只是解决了大页表无需大片连续存储空间问题,但并未解决用较少内存去存放大页表问题,有关此类问题的成功解决方案放在虚拟存储器管理中。
多级页表机构
Intro
对于 64 位的机器,采用两级页表结构是否合适?
使用 4KB 的页面,剩 52 位。若按 4KB 来划分页表,还剩 42 位用于外层页表,因而外层页表有 4KG 个页表项,占 16KGB 的空间
使用 1MB 的页面(220),剩 44 位。若按 1MB 来划分页表,还剩 26 位用于外层页表,外层页表有 64M 个页表项,占 256MB 空间
显然这是不现实的,外层页表过大无法装入一个物理块中
64 位的机器,采用的是多级(4 级以上)页表结构。
电脑的位数通常指的是其 CPU 的位数,这是指 CPU 一次能处理的数据的位数,也就是其寄存器的宽度。例如,32 位的 CPU 一次可以处理 32 位(4 字节)的数据,而 64 位的 CPU 一次可以处理 64 位(8 字节)的数据。
这个位数也决定了 CPU 可以直接寻址的内存空间的大小。32 位的 CPU 可以直接寻址个位置,也就是 4GB 的内存空间。同样,64 位的 CPU 可以直接寻址 个位置,这是一个非常大的空间,远远超过了现在的计算机所装配的实际物理内存。
然而,实际上,操作系统通常会使用虚拟内存系统,这允许每个进程都有自己的地址空间,并且这个地址空间的大小可以超过实际的物理内存。例如,每个进程在 64 位的 Linux 系统中都有一个字节的虚拟地址空间,虽然实际的物理内存可能只有几 GB。
所以,电脑的位数决定了 CPU 的寄存器宽度,一次可以处理的数据的位数,以及可以直接寻址的内存空间的大小。但是实际可用的地址空间可能会因为虚拟内存系统和操作系统的设计而变化。
多级页表实现
通过间接引用将页号分成 k 级,建立页表“树”,减少每级页表的长度
反置页表 IPT Inverted Page Table
Intro
对于在 OS 中同时运行的多个进程,相当大的一部分内存仅被页表占用。若结合了多级分页方案,这会进一步增加存储页表所需的空间,页表占用的内存量可能会成为一个巨大的开销;此外,查找一个物理地址需要读取多个页表,导致查找时间增加。
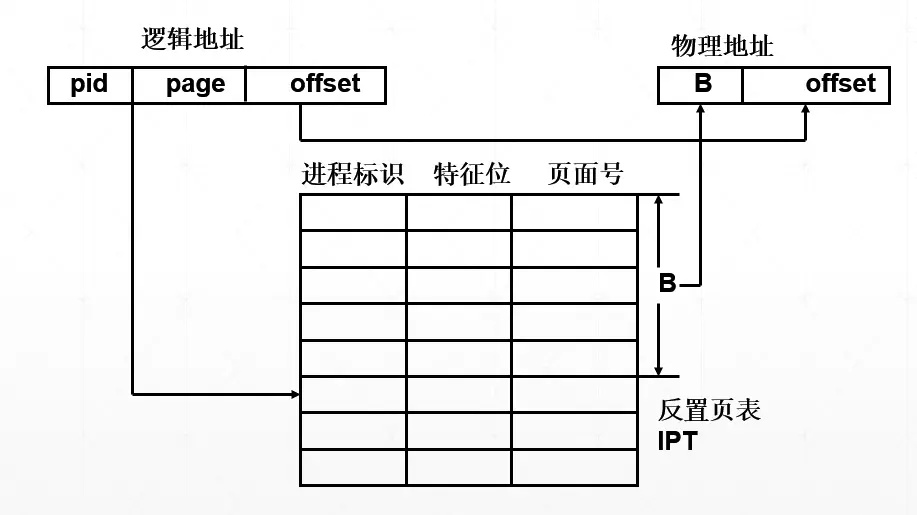
为了有效地利用存储器,引入了反置页表,一个系统中一般只存在一个反向页表,这张页表中的 entry 的数量和内存中 pageframe 的数量是一样的
- IPT 思想:
IPT 是为主存中的每一个物理块建立一个页表项并按照块号排序;
该表每个表项 Entry 包含正在访问该物理块的进程标识 Pid、页面号 Page number 及特征位 Control bits,用来完成主存物理块到访问进程的页号的转换
IPT Entry Struct
- 页号 Page number: It specifies the page number range of the logical address.
- 进程标识 Process id: An inverted page table contains the address space information of all the processes in execution. Since two different processes can have a similar set of virtual addresses, it becomes necessary in the Inverted Page Table to store a process Id of each process to identify its address space uniquely. This is done by using the combination of PID and Page Number. So this Process Id acts as an address space identifier and ensures that a virtual page for a particular process is mapped correctly to the corresponding physical frame.
- 特征位 Control bits: These bits are used to store extra paging-related information. These include the valid bit, dirty bit, reference bits, protection, and locking information bits.
- 链接指针 Chained pointer: It may be possible sometimes that two or more processes share a part of the main memory. In this case, two or more logical pages map to the same Page Table Entry then a chaining pointer is used to map the details of these logical pages to the root page table.
Note: Number of Entries in Inverted page table = Number of frames in Physical Address Space(PAS).
IPT 地址转换过程
给出进程标识和页号,用它们去比较 IPT,若整个反置页表中未能找到匹配的页表项,说明该页不在主存,产生请求调页中断,请求操作系统调入;否则,该表项的序号便是物理块号,块号加上位移,便形成物理地址。
然而,反置页表也有其缺点,比如查找特定虚拟地址对应的物理地址可能会更复杂。为了解决这个问题,一些系统会使用额外的数据结构,如哈希表,基于 Hash 映射值查找对应页表项中的帧号
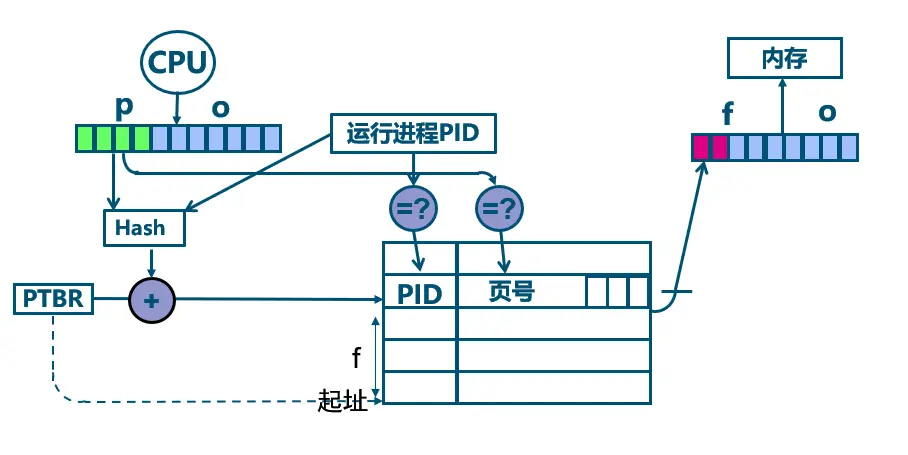
以下是倒排页表(IPT)在引入哈希表后如何转换逻辑地址的过程:
- 当需要访问内存时,操作系统或硬件会使用逻辑地址中的页号和进程 ID 作为哈希函数的输入,计算出哈希值。
- 这个哈希值用于在哈希表中查找相应的页表项。如果存在冲突(即多个 VPN 哈希到同一位置),则使用链接(链表)的方式解决冲突。
- 一旦找到了对应的页表项,就可以得到物理页框号(Physical Frame Number,PFN)。这个 PFN 就是物理地址的一部分。
- 最后,物理地址由 PFN 和原始的页内偏移组成。
通过这种方式,倒排页表结合哈希表可以有效地将逻辑地址转换为物理地址,同时保持查找时间的效率。
Pros
- Reduced Memory Overhead
- Simplified Page Swapping: When a process needs to be swapped out of memory, the IPT can be used to quickly identify all the physical pages that are associated with the process. This can simplify the process of swapping pages and reduce the overall overhead of memory management.
- Improved Cache Performance: Because the IPT is smaller than a Page Table, it can be more easily stored in the CPU cache, which can improve the performance of memory access operations.
基本分段存储管理方式 Segmented Storage Management
分段式存储管理方式的引入
- 方便编程
通常,用户把自己的作业按照逻辑关系划分为若干个段,每个段都是从 0 开始编址,并有自己的名字和长度。因此,希望要访问的逻辑地址是由段名(段号)和段内偏移量(段内地址)决定的
常见段有:主程序段、子程序段、数据段、堆栈段 etc - 分段共享。
一般实现程序和数据共享时都是以信息的逻辑单位(过程、函数或文件)为基础的。
在分页系统中的每一页都只是存放信息的物理单位,其本身并无完整意义,因而不便于实现信息共享。
段是信息的逻辑单位,可以为共享过程建立一个独立的段,更便于实现程序和数据的共享。 - 分段保护。
信息保护同样是对信息的逻辑单位进行保护,因此,分段管理方式能更有效和方便的实现信息保护功能。 - 动态链接。
程序运行时,先将主程序所对应的目标程序装入内存并启动运行,当运行过程中又需要调用某段时,才将该段调入内存并进行链接,分段管理方式更适合实现动态链接。 - 动态增长。
在实际使用中,往往有些段,特别是数据段会随着程序的运行不断增大,而这种增长事先并不知道会增长到多大,采用其它存储管理方式是难以应付的,而分段存储管理却能较好的解决这一问题。
分段式存储管理的基本原理
分段 Segmentation
- 作业地址空间按逻辑信息的完整性被划分为若干个段;
- 每段有段名(或段号),每段从 0 开始编址;
- 段内的地址空间是连续的。
- 许多编译程序支持分段方式,自动根据源程序的情况产生若干个段。
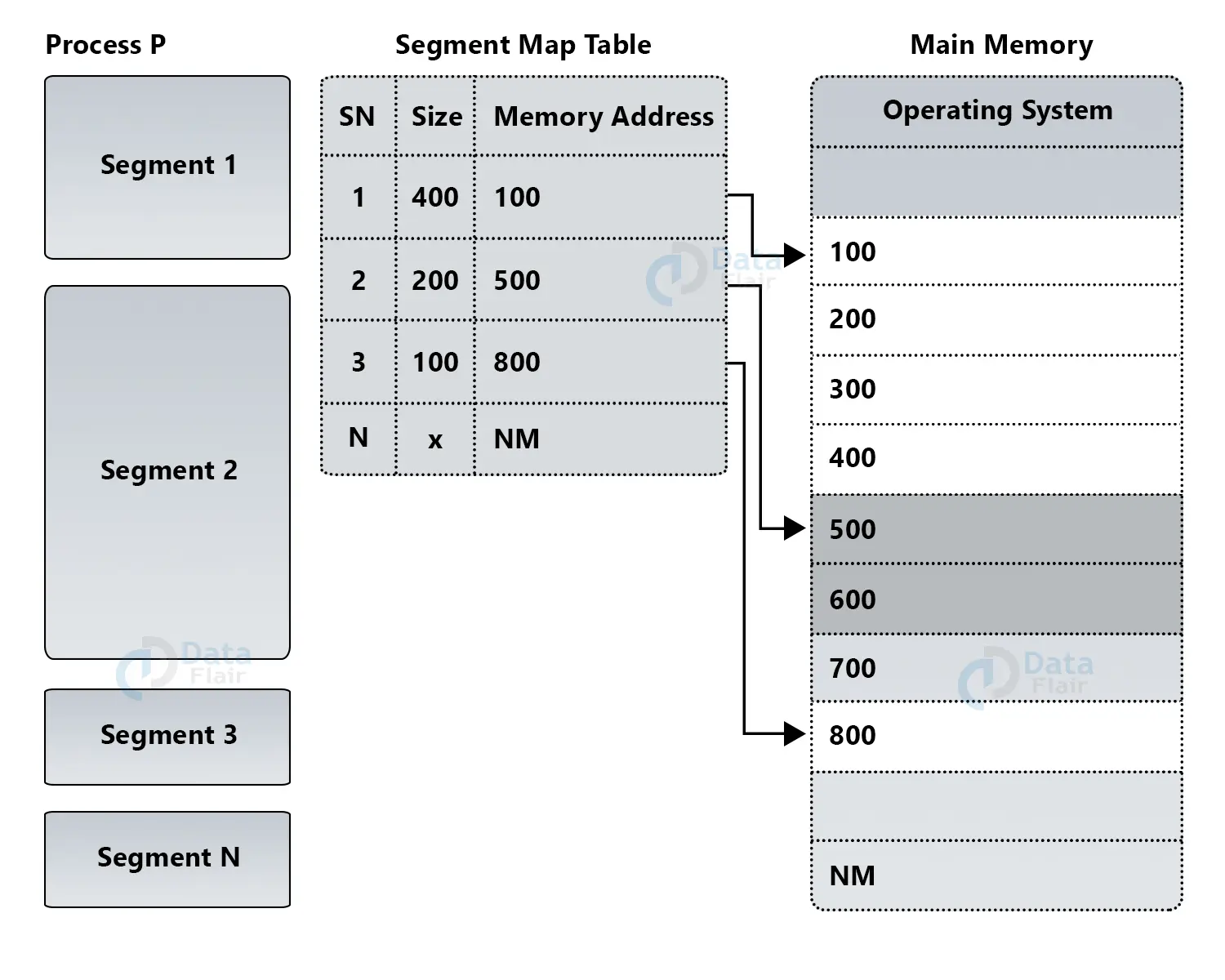
分段的基本原理
在分段管理系统中,对所有地址空间的访问均要求两个成分: (1)段的名字;(2)段内地址。
例如,可按下述调用:CALL [X]|<Y> 转移到子程序X中的入口点YLOAD R1, [A]|<D> 将数组A的D单元的值读入寄存器1STORE R1,[B]|<C> 将寄存器1的内容存入分段B的C单元中
这些符号程序经汇编和装配后,指令和数据的单元地址均由两部分构成:一是表示段名的段号 S;一是位移量 W,即段内地址。
分段管理
分段管理,就是管理由若干分段组成的作业,且按分段来进行存储分配。
实现分段管理的关键在于,如何保证分段(二维)地址空间中的一个作业在线性(一维)的存储空间中正确运行。也就是说,如何把分段地址结构变换成线性的地址结构。和分页管理一样,可采用动态重定位技术,即通过地址变换机构来实现。
优点:
没有内碎片,外碎片可以通过内存紧凑来消除。
便于改变进程占用空间的大小。
段表 Segment Table
为每个段分配一个连续的分区,而进程中的各个段可以离散地移入内存中不同的分区中
段表:每个段在表中占有一个表项,其中记录了该段在内存中的起始地址(又称为“基址”,Base Address)和段长。通常将段表放在内存中,执行中的进程可通过查找段表找到每个段所对应的内存区。作用为实现从逻辑段到物理内存区的映射
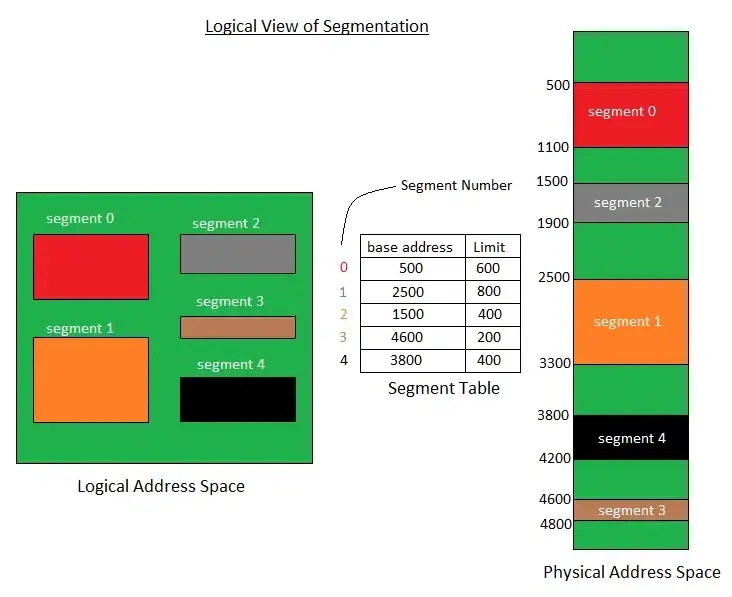
地址变换机构 Address Translation
段表寄存器(Segment Table Register,STR)
- 根据段表寄存器的内容找到该作业的段表地址;
- 检索段表,得到该段在主存的起始地址;
- 将段的主存起始地址和位移量 W 相加,即得访问主存的物理地址
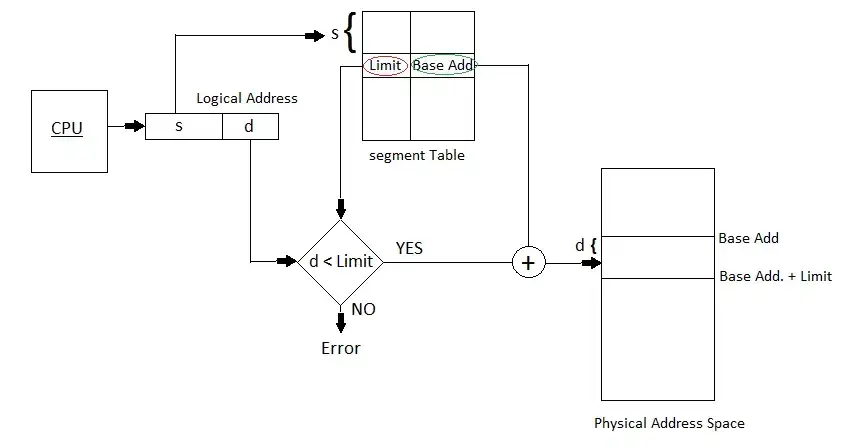
若段表放在内存中,每访问一个数据需要访问内存 2 次,可设置联想存储器(快表),以提高访问速度。
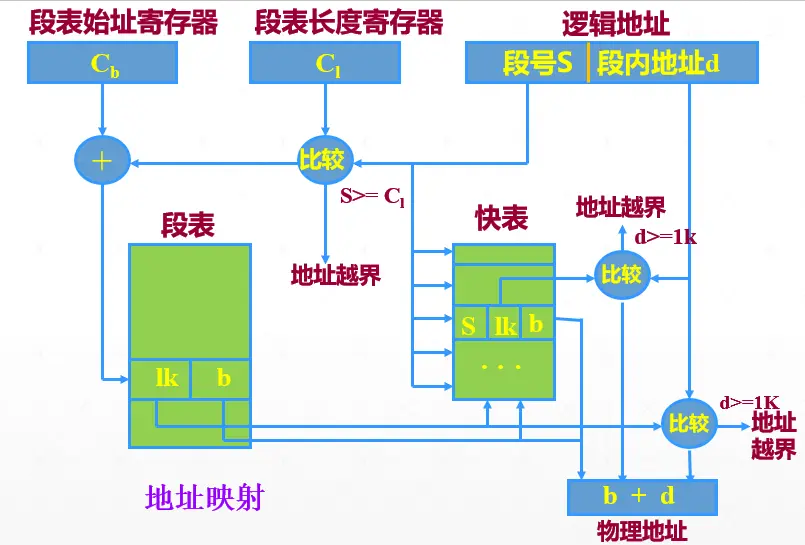
段的共享和保护
信息共享
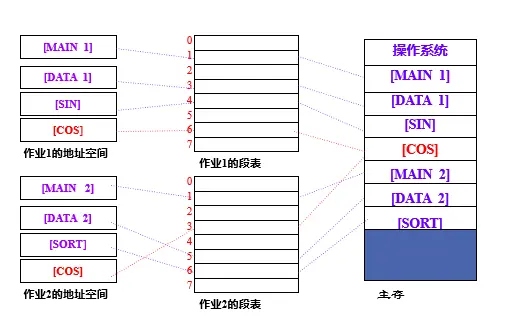
分页系统实现程序段的共享较为困难。分段易于实现段的共享和段的保护。
可重入代码(Reentrant Code, 纯代码)是一种允许多个进程同时访问的代码(可共享),且是一种不允许任何进程对其进行修改的代码。
例如一个多用户系统可接纳 40 个用户,它们都执行一个文本编辑程序(ED),ED 代码共 160K(ED 可共享),每个用户还有 40K 的数据区(DA)。
- 不采用信息共享时需占用的内存空间
- 采用信息共享后占用的内存空间
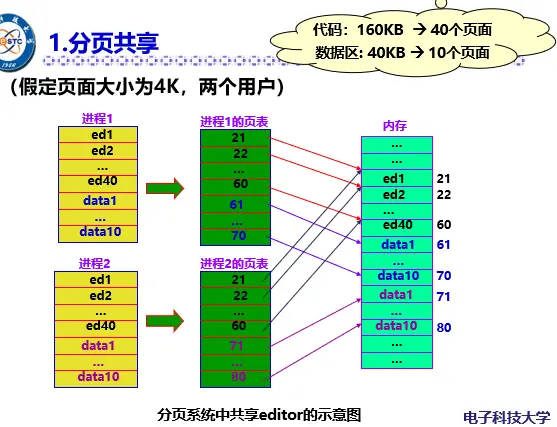
分页共享
在分页存储管理中,进程被划分为固定大小的页。当两个或更多的进程需要访问相同的信息时,可以使用分页共享。例如,当多个进程运行相同的程序或访问相同的只读文件时,它们可以共享相同的代码页或数据页。这种方式的优点是可以节省内存空间,因为相同的信息只需要在内存中存储一次。此外,分页共享也可以用于实现进程间的通信。
对于数据页面,实现起来比较简单。因为这个数据页面可以安排在诸作业地址空间中的任何一页面上。
如果多个进程(或作业)要共享同一个代码页,那么这个代码页必须在所有共享它的进程的地址空间中处于相同的位置(即具有相同的页号)。这是因为代码页中的跳转或引用指令的目标地址通常在链接阶段就确定了。
分段共享
在分段存储管理中,进程被划分为多个具有不同长度和功能的段。分段共享允许多个进程共享一个或多个段。这在一些情况下是非常有用的。例如,当多个进程需要执行相同的函数或访问相同的数据结构时,它们可以共享相同的代码段或数据段。分段共享的优点是它可以更灵活地管理内存,因为每个段的大小可以根据需要进行调整。此外,分段共享也可以用于实现进程间的通信。
段页式存储管理 Segment Paging
段页式存储管理的引入
分页管理内存管理效率高
- 没有外零头
- 内零头小
分段管理符合模块化思想 - 每个分段都具备完整的功能
- 方便代码共享、保护
- 没有内零头,存在外零头
段式存储在内存保护方面有优势,页式存储在内存利用和优化转移到后备存储方面有优势。两者结合,形成段页式存储管理方式。
原理:分段和分页相结合。先将用户程序分段,每段内再划分成若干页,每段有段名(段号),每段内部的页有一连续的页号。
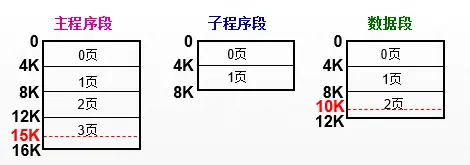
下图为段页式系统中一个作业的地址空间结构,页面尺寸为 4KB。由图可见,该作业有三个分段,第一段为 15KB,占 4 页,最后一页有 1KB 未用;第二段为 8KB,恰好占满 2 页;第三段为 10KB,占 3 页;而最后一页有 2KB 未用。和分页系统一样,这些未写满的页,在装入主存空间后,依然存在内零头问题。
- 内存划分:按页式存储管理方案。
- 内存分配:以页为单位进行离散分配。
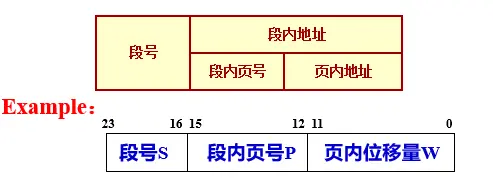
- 逻辑地址结构:由于段页式系统给作业地址空间增加了另一级结构现在地址空间如下所示
- 段号 Segment numbers(S)
- 段内页号 Page number (P)
- 页内相对地址(位移量)The offset number (W)
综合了分段和分页技术的优点,既能有效地利用存储空间,又能方便用户进行程序设计。但是,实现段页式存储管理系统需要增加硬件成本,系统的复杂度和管理开销也大大增加。因此,段页式存储管理技术适合于大、中型计算机系统,不太适合小型、微型计算机系统。
地址变换机构 Address Translation
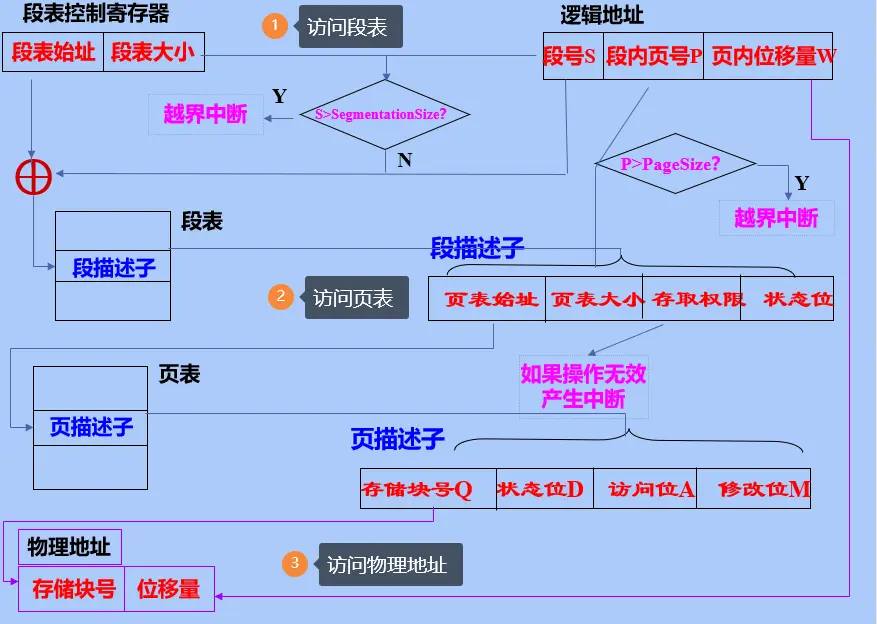
- 首先,从段表寄存器从获得进程段表的起始地址,根据该地址,查找进程的段表。
- 然后,根据逻辑地址指定的段号检索段表,找到对应段的页表起始地址。
- 再根据逻辑地址中指定的页号检索该页表,找到对应页所在的物理块号。
- 最后,用物理块号加上逻辑地址中指定的页内偏移量,形成物理地址。
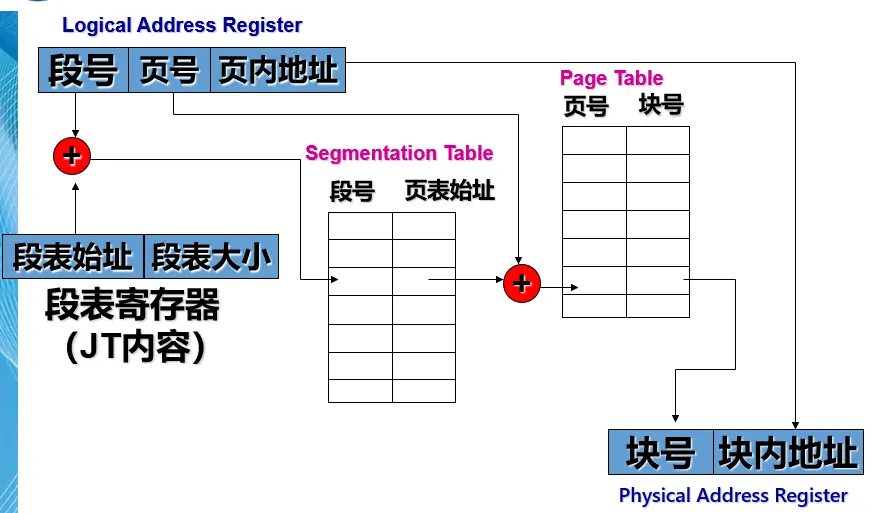
段页式存储管理
在段页式存储管理方式中,每访问一次数据,需访问 次内存。
- 第一次访问内存中的段表
- 第二次访问内存中的页表
- 第三次访问相应数据。
可以设置快表,表项应包括段号、页号、物理块号
Swap
Intro
对换指把内存中暂不能运行的进程或暂时不用和程序和数据,换到外存上,以腾出足够的内存空间,把已具备运行条件的进程,或进程所需要的程序和数据,换入内存。
对换是系统行为,是提高内存的利用率的有效措施。
常用于多道程序系统或小型分时系统中,与分区存储管理配合使用。
实现:可在系统中设一对换进程,以执行换进内存、换出至外存操作。
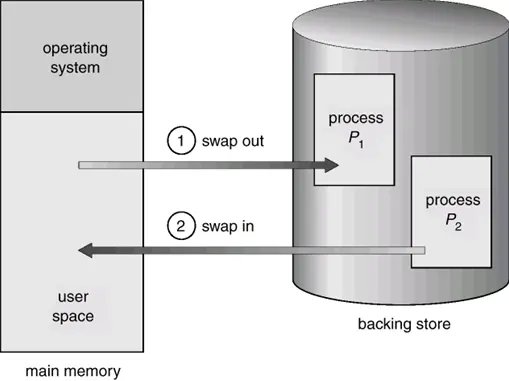
对换技术,最早用在分时系统 UNIX 中。
在任何时刻,在该系统的主存中只保存一个完整的用户作业,当其运行一段时间后,或由于分配给它的时间片已用完,或由于需要其它资源而等待,系统就把它交换到辅存,同时把另一个作业调入主存让其运行。这样,可以在存储容量不大的小型机上实现分时系统。
原理
分类
- 整体对换(进程对换)
对换以整个进程为单位,用于分时系统,以解决内存紧张的问题; - 页面对换/分段对换
对换以“页”或“段”为单位进行“部分对换”,该方法是实现请求分页及请求分段存储器的基础,支持虚存系统。
功能
为实现对换,系统需要三方面的功能:
- 对换空间的管理
- 进程的换入
- 进程的换出
对换空间的管理
外存被分为两部分,文件区和对换区
文件区用于存放文件,对它的管理应重在如何提高存储空间的利用率。所以对它采取离散分配方式。即一个文件可根据当前外存的使用情况,被分成多块,分别存储到不邻接的多个存储区域中,用指针相连。
对换区存放从内存换出的进程,它们在外存的存放时间较短,换入、换出频繁。对对换区的管理应重在提高进程的换入换出速度。因此采用连续分配方式。即把一个换出的进程存放到一个连续的存储空间中。
为了能对对换区中的空闲盘块进行管理,在系统中应配置相应的数据结构,以记录外存的使用情况。
空闲分区表或空闲分区链。在空闲分区表中的每个表目应包含两项,即对换分区首址和对换区长度,它们的基本单位都是盘块。
对换区的分配,是采用连续分配方式。因而对对换区空间的分配与回收,与动态分区方式时内存的分配与回收方法雷同。
分配算法可以是首次适应算法、循环首次适应算法和最佳适应算法。
回收操作也可分为四种情况
为了能对交换区中的空闲盘块进行管理,在系统中应配置相应的数据结构,盘块的大小和操作系统的具体文件系统有关系;比如 fat32 的盘块大小为 4KB,内存分配的单位是字节,外存(硬盘)分配的单位是盘块
进程的换进与换出
换出(swap out)
首先选择阻塞或睡眠状态的进程,若有多个,按优先级由低到高进行选择。若没有此状态进程,则选择就绪状态的,仍然按优先级由低到高进行选择。
为避免某进程被频繁的换入换出,还应考虑进程在内存中的驻留时间,优先选择驻留时间长的进程。
换入(swap in)
① 从 PCB 集合中查找“就绪且换出”的进程,有多个,则选择换出时间最长的。
② 根据进程大小申请内存,成功则读入,否则要先执行换出,再换入。
③ 若还有可换入进程,则转向 ①。直至无“就绪且换出”进程或无法获得足够内存空间为止。
Comparison
| S.NO | Paging | Segmentation |
|---|---|---|
| 1 | In paging, the program is divided into fixed or mounted size pages. | In segmentation, the program is divided into variable size sections. |
| 2 | For the paging operating system is accountable. | For segmentation compiler is accountable. |
| 3 | Page size is determined by hardware. | Here, the section size is given by the user. |
| 4 | It is faster in comparison to segmentation. | Segmentation is slow. |
| 5 | Paging could result in internal fragmentation. | Segmentation could result in external fragmentation. |
| 6 | In paging, the logical address is split into a page number and page offset. | Here, the logical address is split into section number and section offset. |
| 7 | Paging comprises a page table that encloses the base address of every page. | While segmentation also comprises the segment table which encloses segment number and segment offset. |
| 8 | The page table is employed to keep up the page data. | Section Table maintains the section data. |
| 9 | In paging, the operating system must maintain a free frame list. | In segmentation, the operating system maintains a list of holes in the main memory. |
| 10 | Paging is invisible to the user. | Segmentation is visible to the user. |
| 11 | In paging, the processor needs the page number, and offset to calculate the absolute address. | In segmentation, the processor uses segment number, and offset to calculate the full address. |
| 12 | It is hard to allow sharing of procedures between processes. | Facilitates sharing of procedures between the processes. |
| 13 | In paging, a programmer cannot efficiently handle data structure. | It can efficiently handle data structures. |
| 14 | This protection is hard to apply. | Easy to apply for protection in segmentation. |
| 15 | The size of the page needs always be equal to the size of frames. | There is no constraint on the size of segments. |
| 16 | A page is referred to as a physical unit of information. | A segment is referred to as a logical unit of information. |
| 17 | Paging results in a less efficient system. | Segmentation results in a more efficient system. |
Ref
data-flair memory-management-in-computer
Inverted page tables
Inverted Page Table in Operating System
操作系统基本分段存储管理方式
Storage Management PartⅡ